
Nemotron-3-Super 完全ガイド【2026年3月】|NVIDIAが放つ120Bパラメータで12Bしか動かないMoEモデルの全貌
2026年3月11日、NVIDIAはNemotron-3-Superを公開しました。総パラメータ数120B(1,200億)でありながら、推論時にアクティブになるのはわずか12B(120億)──。この「120Bの知識を12Bのコストで使える」という魔法のようなアーキテクチャが、ローカルLLMの常識を書き換えようとしています。
しかも、ただのMoE(Mixture of Experts)ではありません。Mamba-2の線形時間処理とTransformerの連想記憶、そしてNVIDIA独自のLatentMoEを組み合わせた「ハイブリッド・アーキテクチャ」です。コンテキストウィンドウは最大100万トークン。マルチエージェント向け推論機能付き。商用利用可。そしてOllamaで動く。
本記事では、Nemotron-3-Superの技術仕様から実行方法、競合比較、そして「本当にローカルで動かす価値があるのか?」まで、開発者が判断に必要なすべてを解説します。
最終更新: 2026年3月14日
Nemotron-3-Superとは何か──Nemotronファミリーの全体像
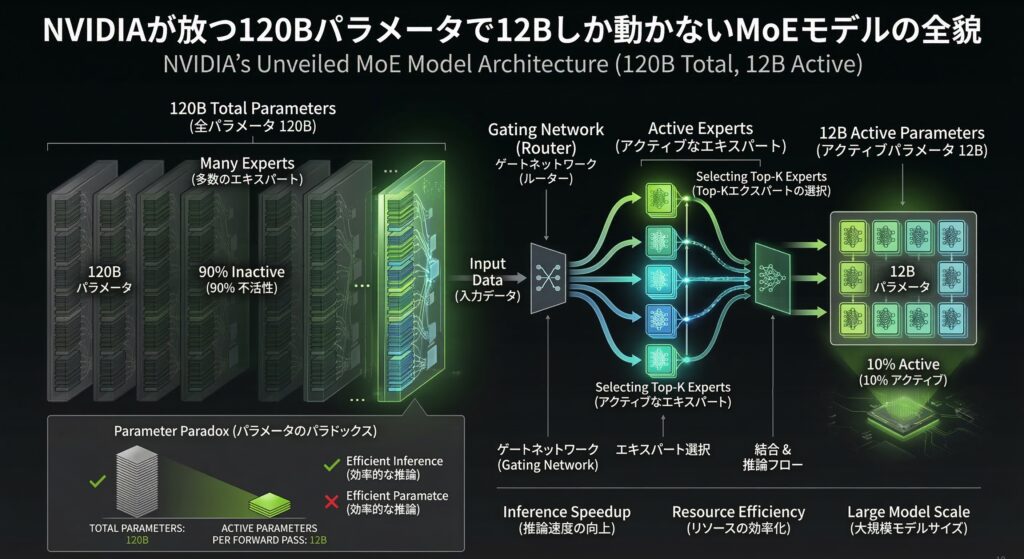
Nemotron-3-Super(正式名称: Nemotron-3-Super-120B-A12B)は、NVIDIAが開発したオープンウェイトのLLMです。「120B-A12B」の意味は、総パラメータ数120Bのうち、1トークンあたり12Bのみアクティブになるということ。
NVIDIAのNemotronファミリーは、2024年のNemotron-4(15B / 340B)から始まり、2025年4月のLlama-3.1-Nemotron-Ultra(253B)を経て、第3世代に到達しました。Nemotron-3世代は3つのサイズ展開です。
| モデル | 総パラメータ | アクティブ | 用途 | 状態 |
|---|---|---|---|---|
| Nano | 30B | ~3B | 軽量・エッジ向け | 公開済み |
| Super ← 本記事 | 120B | 12B | エージェント・推論 | 公開済み |
| Ultra | 未公開 | 未公開 | 最高推論性能 | 2026年前半予定 |
Superの立ち位置は「コスト効率と性能のスイートスポット」です。Nanoほど小さくはないが、Ultraほどの計算リソースは不要。マルチエージェントシステムやIT自動化など、高頻度で大量のトークンを生成する用途に最適化されています。
対応言語は英語、フランス語、ドイツ語、イタリア語、日本語、スペイン語、中国語の7言語。ライセンスはNVIDIA Nemotron Open Model Licenseで、商用利用が可能です。
アーキテクチャ解説──Mamba × Transformer × LatentMoE
Nemotron-3-Superの最大の技術的特徴は、3種類のレイヤーを交互に積み重ねるハイブリッド設計です。単純なTransformerでもMoEでもない、NVIDIAが「ハイブリッド Mamba-Transformer Mixture of Experts」と呼ぶアーキテクチャです。
3つのレイヤーの役割分担
1. Mamba-2レイヤー──シーケンス長に対して線形時間で処理できる状態空間モデル(SSM)です。従来のTransformerのAttentionはシーケンス長の2乗に比例してコストが増大しますが、Mamba-2はどれだけ長い入力でも計算量が線形にしか増えません。これが100万トークンのコンテキストウィンドウを実現する基盤です。
2. Transformer Attentionレイヤー──Mambaだけでは「特定の情報をピンポイントで検索する」能力(連想記憶)が弱いため、従来型のAttentionレイヤーも組み込んでいます。長文中の特定の事実を正確に参照する必要がある場面で威力を発揮します。
3. LatentMoEレイヤー──NVIDIAが独自に開発したMoEの改良版です。従来のMoEでは、トークンの埋め込みをそのままルーターに渡してエキスパートを選択します。LatentMoEは、トークン埋め込みをまず低ランクの潜在空間に圧縮してからルーティングと計算を行い、結果をフル次元に投影します。この工夫により、同じ計算コストで従来の4倍のエキスパート数を配置でき、ルーティングの通信コストも約4分の1に削減されます。
具体的なレイヤー配置パターンは以下の繰り返しです。
Mamba-2 → LatentMoE → Mamba-2 → Attention → Mamba-2 → LatentMoE → …(5ブロック群で反復)
Multi-Token Prediction(MTP)
さらに、Nemotron-3-Superは各位置から複数の将来トークンを同時に予測するMTP機能を搭載しています。これは実質的に「組み込みの投機的デコーディング」であり、構造化テキスト(JSON、コードなど)の生成で最大3倍の速度向上が報告されています。
NVFP4ネイティブ学習
量子化は後付けではなく、最初の勾配更新からNVFP4(4ビット浮動小数点)で学習されています。これにより、量子化による精度劣化が最小限に抑えられ、NVIDIA Blackwell(B200)GPU上ではH100のFP8比で4倍の推論速度を実現します。
そもそもMoEとは何か──「エキスパートの分業」を直感的に理解する
MoE(Mixture of Experts)は、2025年以降のフロンティアLLMでほぼ標準となったアーキテクチャです。Nemotron-3-Superを理解するために、基本から解説します。
通常のTransformerとの違い
通常のTransformer(Denseモデル)では、すべてのパラメータがすべてのトークンの処理に使われます。70Bモデルなら、1トークンの処理に700億パラメータ全体が動きます。
MoEでは、FFN(Feed-Forward Network)レイヤーを複数の「エキスパート」に分割します。各エキスパートは独立したFFNで、特定の種類のトークンに特化しています。そして、ゲーティングネットワーク(ルーター)が各トークンに対して「どのエキスパートを使うか」を決定します。
例えるなら、Dense モデルは「なんでもやる万能社員1人」、MoEは「専門家チーム10人のうち、毎回2人が対応する組織」です。全員分の給料(VRAM)は必要ですが、実際に動くのは2人分のコストで済みます。
120B / 12Bの意味
Nemotron-3-Superの「120B-A12B」は、10人のエキスパートのうち1人分だけが毎回アクティブになる、というイメージです。120Bの知識量を持ちながら、推論コストは12Bのdenseモデルと同等。ただし、VRAMは120B分必要──ここがMoEの最大の注意点です。
MoEの歴史的文脈
MoEの概念は1991年のHintonらの論文に遡りますが、LLMに本格適用されたのは2017年のShazeerらの研究(137B LSTM MoE)からです。2023年にMistral AIがMixtral 8x7Bをオープンソース公開して一般に普及し、2024年のDeepSeek-V3で「細粒度エキスパート(256個)」の有効性が実証されました。2025年時点で、Llama 4、Gemini、GPTファミリーなど主要なフロンティアモデルのほぼすべてがMoEを採用しています。
学習プロセス──25兆トークンと3段階の鍛錬
Nemotron-3-Superの学習は3フェーズで構成されています。
フェーズ1: プリトレーニング──25兆トークン(10兆のユニークキュレーショントークン、100億の推論特化トークン、1,500万のコーディング問題を含む)。最初の勾配更新からNVFP4で学習する「ネイティブ低精度学習」を採用し、計算効率を最大化しています。
フェーズ2: Supervised Fine-Tuning(SFT)──約4,000万のポストトレーニングコーパスから厳選された約700万サンプルで教師あり微調整。推論、指示追従、コーディング、安全性、マルチステップのエージェントタスクをカバーしています。
フェーズ3: マルチ環境強化学習(RL)──21の環境構成、約120万の環境ロールアウト、約37のデータセットを使用。NVIDIA独自のNeMo GymおよびNeMo RLライブラリで実行されました。10個のデータセットは公開されています。
特筆すべきは、RLフェーズでマルチエージェントシナリオを含む環境で学習している点です。単に「正しい回答を出す」だけでなく、「他のエージェントと協調して問題を解決する」能力が学習段階から組み込まれています。
ベンチマーク──数学94点、コーディング78点の実力
公式ベンチマークの主要結果を整理します。Standard(フル精度)、FP8、NVFP4の3バリアントの比較です。
| カテゴリ | ベンチマーク | Standard | FP8 | NVFP4 |
|---|---|---|---|---|
| 汎用知識 | MMLU-Pro | 83.73 | 83.63 | 83.33 |
| 推論 | HMMT Feb25(ツール使用) | 94.73 | 94.38 | 95.36 |
| GPQA(ツールなし) | 79.23 | 79.36 | 79.42 | |
| LiveCodeBench v6 | 78.69 | 78.44 | 78.44 | |
| HLE(ツールなし) | 18.26 | 17.42 | 17.42 | |
| エージェント | PinchBench | 85.6% | 同クラスオープンモデル最高 | |
| チャット | Arena-Hard-V2 | 73.88 | 76.06 | 76.00 |
| 長文脈 | RULER-500 @128K | 96.79 | 96.85 | 95.99 |
| RULER-500 @256K | 96.60 | 96.33 | 96.52 | |
| RULER-500 @512K | 96.09 | 95.66 | 96.23 | |
| 多言語 | MMLU-ProX(平均) | 79.35 | 79.21 | 79.37 |
注目すべきポイントをまとめます。
HMMT 94.73は衝撃的です。HMMTはハーバード・MIT数学トーナメントの問題集で、大学レベルの高度な数学推論を要求します。ツール使用ありとはいえ、12Bアクティブでこのスコアは異常値です。
NVFP4でもほぼ性能低下がない。MMLU-Proで83.73→83.33(差-0.40)、GPQAでは79.23→79.42とむしろ上昇。ネイティブNVFP4学習の効果がはっきり出ています。
長文脈性能が128K→512Kで劣化しない。RULER-500が128Kで96.79、512Kで96.09。わずか-0.70ポイント。Mamba-2の線形時間処理が文脈長への耐性を確保しています。
PinchBench 85.6%はエージェント性能の証明。NVIDIAは「同クラスのオープンモデルで最高」と主張しています。マルチエージェントシステムでのツール使用・協調動作を評価するベンチマークで、このスコアは実用レベルです。
Ollamaで動かす──実行方法とハードウェア要件
Ollamaでの提供は以下のバリエーションです。
| タグ | 量子化 | ファイルサイズ | 備考 |
|---|---|---|---|
| 120b-a12b(デフォルト) | Q4_K_M | 87GB | 最もバランスが良い |
| 120b-a12b-q8_0 | Q8_0 | 132GB | 高精度 |
| 120b-a12b-bf16 | BF16(フル精度) | 247GB | 研究用 |
実行コマンドはシンプルです。
ollama run nemotron-3-super推論(Reasoning)機能のON/OFFは、チャットテンプレートのフラグで切り替え可能です。NVIDIA API経由ではreasoning_effortを"none"/"low"/"high"で設定できます。NVIDIA APIのデフォルト設定はtemperature: 1.0、top_p: 0.95です。
現実的なハードウェア要件
ここが最も重要な話です。MoEモデルはアクティブパラメータが少なくても、全パラメータをVRAMに載せる必要があります。Q4_K_M量子化の87GBというファイルサイズがそのまま必要VRAM量の目安になります。
つまり、個人のGPU1枚(24GB〜48GB)では動きません。現実的な選択肢は以下です。
- NVIDIA H100 80GB × 2枚以上(企業・研究機関向け)
- NVIDIA A100 80GB × 2枚以上(同上)
- Mac Studio M2/M3/M4 Ultra 192GB(統合メモリで理論上可能だが低速)
- クラウド実行(
ollama run nemotron-3-super:cloudでNVIDIA APIを利用)
Ollamaのコンテキストウィンドウはデフォルト256Kに設定されています。ネイティブは100万トークンですが、それを活用するにはさらに多くのVRAMが必要です。
競合MoE比較──DeepSeek-V3・Qwen3・Llama 4との位置関係
2026年3月時点の主要MoEモデルとの比較です。
| モデル | 総パラメータ | アクティブ | コンテキスト | 特徴 | ライセンス |
|---|---|---|---|---|---|
| Nemotron-3-Super | 120B | 12B | 1M | Mamba+MoE、エージェント特化 | 商用可 |
| DeepSeek-V3 | 671B | 37B | 128K | 256エキスパート、コスト革命 | 商用可 |
| Qwen3-235B-A22B | 235B | 22B | 32K(YaRN: 131K) | 128エキスパート、多言語 | Apache 2.0 |
| Llama 4 Maverick | 400B | 17B | 1M | 128エキスパート、マルチモーダル | Llama License |
| Mixtral 8x22B | 141B | 39B | 64K | 8エキスパート、Apache 2.0 | Apache 2.0 |
テーブルだけでは見えない設計思想の違いが重要です。
DeepSeek-V3は「256個の小さなエキスパート」で細粒度ルーティングを追求。総パラメータ671Bは桁違いに大きく、ローカル実行は非現実的ですが、API利用時の性能は最高クラスです。
Llama 4 Maverickは同じ100万トークンのコンテキストを持ちますが、「128エキスパートから2つ選ぶ」というDeepSeek寄りの設計。マルチモーダル対応が強みです。
Nemotron-3-Superの差別化ポイントは、Mamba-2による線形時間処理とLatentMoEの組み合わせです。同じ100万トークンでも、TransformerベースのLlama 4 Maverickとは計算効率のスケーリング特性が根本的に異なります。長いコンテキストほどNemotronが有利になる設計です。
ユースケース──マルチエージェントと長文脈が輝く場面
NVIDIAは「マルチエージェントアプリケーション向けに最適化」と明言しています。具体的にどういう場面で強みが出るのか、整理します。
1. マルチエージェントシステム
NVIDIAの分析によると、マルチエージェントシステムは通常のチャットの最大15倍のトークンを生成します。オーケストレーター → プランナー → 実行者 → レビュアーのように複数のエージェントが協調する場合、モデルの推論コストが直接的にシステムの運用コストに反映されます。120Bの知識量を12Bのコストで処理できるMoEの特性は、この用途で最大の恩恵をもたらします。
2. IT運用の自動化
ITチケットの分類・対応、ログ分析、インシデント対応の自動化。大量の定型タスクを高速に処理する必要があり、PinchBench 85.6%のエージェント性能が活きる場面です。
3. 長文ドキュメント処理
100万トークンのコンテキストウィンドウは、書籍1冊分、法律文書数百ページ、大規模コードベース全体を一度に処理できます。RULER-500で512Kトークンでも96.09を維持する長文脈耐性は、RAGなしでのドキュメント分析を可能にします。
4. 構造化データ生成
MTPによる最大3倍の速度向上は、JSON、XML、SQLなどの構造化テキスト生成で特に効果的です。API応答のスキーマ生成、データ変換パイプラインなど、予測可能なパターンが多い出力で真価を発揮します。
筆者の分析──NVIDIAの本当の狙いと「動かす価値」の正直な評価
NVIDIAがLLMを「無料で配る」理由──ハードウェア戦略としてのオープンモデル
NVIDIAはGPUメーカーです。LLMそのもので利益を出す必要はありません。Nemotron-3-Superを無料で公開する理由は明快で、「このモデルを最高性能で動かすにはNVIDIA GPUが必要」だからです。
特にNVFP4のネイティブ学習は、NVIDIA Blackwell(B200)GPU上で最大性能を発揮するよう設計されています。LatentMoEのルーティング最適化も、NVIDIAのGPU間通信技術(NVLink、NVSwitch)が前提です。これは「ハードウェアで稼ぐためのソフトウェア戦略」であり、MetaのLlama(広告エコシステムのためのオープンモデル)と同じ構造です。
この事実自体は批判ではありません。むしろ、NVIDIAには「このモデルが自社GPUで最高のパフォーマンスを出す」ことへの強いインセンティブがあるため、ハードウェア最適化の品質は信頼できると評価できます。問題は、AMD MI300XやIntel Gaudi上での性能が最適化されない可能性があることです。特定ベンダーへのロックインリスクは、企業導入時に必ず考慮すべき点です。
リリースタイミングの意味──Llama 4との正面衝突
Nemotron-3-Superが2026年3月にリリースされたタイミングは偶然ではないと考えます。MetaがLlama 4 Maverick(400B/17Bアクティブ、1Mコンテキスト)を公開したほぼ同時期です。
NVIDIAのメッセージは明確です。「Llama 4もいいが、NVIDIAのGPUに最適化されたモデルを使いませんか?」──Llama 4はPyTorch標準で動きますが、Nemotron-3-SuperはNVIDIA NIM、TensorRT-LLM、vLLMでの最適化が前提です。「同じNVIDIA GPUを使うなら、NVIDIAが自社GPU向けに最適化したモデルの方が速い」という論理は、企業のインフラ担当者にとって無視できない訴求力があります。
「12Bアクティブ」の落とし穴──VRAM詐欺に注意
「12Bしか使わないから軽い」という誤解が広まりそうですが、これは危険な誤解です。推論コスト(FLOPS)が12B相当なだけで、メモリ(VRAM)は120B分必要です。87GBのQ4_K_M量子化モデルを載せるには、どう工夫しても80GB超のVRAMが要ります。
MoEの「安い」は「同じ知識量のDenseモデルに比べて推論速度が速い」という意味であり、「少ないVRAMで動く」という意味ではありません。ここを混同すると、購入するハードウェアを間違えます。さらに、MoEには固有の帯域幅ボトルネック問題があります。エキスパート間のall-to-all通信がGPU間のバスを圧迫するのです。LatentMoEがルーティング通信を約4分の1に削減すると謳うのは、まさにこの問題への対処であり、NVIDIAのNVLink/NVSwitchという高帯域インターコネクトがあって初めて真価を発揮します。
LatentMoEの技術的洞察──本当に革新的か
LatentMoEは「低ランク潜在空間に圧縮してからルーティング」という手法で、DeepSeek-V3のMulti-head Latent Attention(MLA)とアプローチが似ています。両者とも「低ランク圧縮でコストを下げる」発想です。ただし、MLAはKVキャッシュの圧縮、LatentMoEはエキスパートルーティングの圧縮と、適用対象が異なります。
「同じコストで4倍のエキスパート」は印象的な数字ですが、エキスパートの具体的な数はNVIDIAが公開していません。「従来比4倍」が何と比較した4倍なのか──自社の前世代モデルなのか、Mixtralのような標準MoEなのか──が不明確です。技術的に面白いアイデアですが、再現可能性が検証されるまでは盲目的に信じるべきではありません。
Mamba-2への賭け──SSMが主流になれなかったらどうなるか
正直に言えば、現時点ではMambaの優位性は「長文脈のスケーリング効率」に限定されます。128K以下のコンテキストでは、純粋なTransformerモデル(DeepSeek-V3やQwen3)との差は小さいでしょう。
RULER-500が512Kで96.09というスコアは、「長いほど劣化する」という常識を覆しています。これはMamba-2アーキテクチャの実力であり、ベンチマーク詐称では得られない結果です。
しかし、NVIDIAがMamba-2に賭けていることのリスクも指摘すべきです。2026年3月時点で、主要なフロンティアモデル(GPT、Claude、Gemini)はいずれも純粋なTransformerベースです。Mambaを採用したフロンティアモデルはまだ存在しません。NVIDIAがハイブリッドアーキテクチャで先行することは、SSMが主流化すれば先見の明になりますが、Transformerが効率面でも十分に進化すれば(例えばFlashAttention-3のような最適化が続けば)、アーキテクチャの複雑さがデメリットになる可能性もあります。
私の予測では、ハイブリッドアプローチが今後1〜2年で主流になる可能性は高いと見ています。理由は、100万トークン以上のコンテキストが標準化する流れの中で、Attentionの二次コストは避けられない壁だからです。ただし、それがMamba-2なのか、別のSSMバリアントなのかは未知数です。
「オープンウェイト」の実態──Apache 2.0とは違う
Nemotron-3-Superは「NVIDIA Nemotron Open Model License」で公開されていますが、これはApache 2.0やMIT Licenseとは異なるNVIDIA独自のライセンスです。商用利用は許可されていますが、Mistral AIのMixtral(Apache 2.0)やQwen3(Apache 2.0)と同じ意味の「オープン」ではありません。
企業導入時には、ライセンスの具体的な制約条件(再配布条件、派生モデルの扱い等)を法務部門で確認することを推奨します。「オープンウェイト = 何でもOK」と思い込むのはリスクです。
日本語性能の正直な評価──ベンチマーク不足という現実
対応7言語に日本語が含まれ、MMLU-ProX(多言語版MMLU-Pro)で79.35を記録しているのは好材料です。しかし、日本語単独のベンチマーク(JMT-Bench、JGLUE等)の公式スコアが一切公開されていません。
「7言語対応」と書いてあっても、英語と日本語で性能差が大きいケースはオープンモデルでは珍しくありません。特にMoEモデルでは、特定言語のエキスパートが十分に学習されていない可能性があります。日本語で本格運用を検討するなら、自社のユースケースで必ず実測すべきです。MMLU-ProXの多言語平均スコアだけで日本語性能を判断するのは危険です。
誰が使うべきか──正直な推奨
使うべき人:
- マルチエージェントシステムを構築しており、推論コストを下げたい企業
- 100万トークンのコンテキストを活用する長文処理パイプラインがある開発者
- NVIDIA GPU(H100/B200)を既に保有し、NIMやTensorRT-LLMで本番デプロイする環境がある
- SSM/ハイブリッドアーキテクチャの研究を進めたい研究者
使わなくていい人:
- 個人のRTX 4090(24GB)でローカルLLMを楽しみたい人 → Qwen3-30B-A3BやGemma3の方が現実的
- 単純なチャットボットを作りたい人 → DeepSeek-R1の蒸留版(7B/14B)で十分
- API経由で使うだけの人 → Claude、GPT-4o、Geminiの方がエコシステムが成熟している
- AMD/Intel GPUを使っている人 → 最適化の恩恵が得られないため、Llama 4やQwen3が無難
総合評価──「野心的だが、万人向けではない」
Nemotron-3-Superは、技術的には2026年3月時点で最も野心的なオープンMoEモデルです。Mamba-2 × Transformer × LatentMoEのハイブリッドは、どの競合も採用していないユニークな設計であり、長文脈とエージェント性能で明確な差別化ができています。
しかし、その恩恵を受けるには最低でも80GB以上のVRAMが必要であり、個人レベルのローカルLLMとしてはハードルが高いのが現実です。NVIDIAの真の狙いは「このモデルで遊んでもらう」ことではなく、「企業がNVIDIA GPUで大規模エージェントシステムを構築する際の第一選択肢になる」ことです。
私の評価をまとめると: 技術的完成度は5段階で4.5。ただし実用的なアクセシビリティは2.5。「すごいモデルだが、動かせる人が限られる」──これがNemotron-3-Superの正直な立ち位置です。NVIDIA GPU環境を持つ企業にとっては真剣に検討すべきモデルであり、そうでない人にとっては「すごい技術を鑑賞する対象」に留まるでしょう。
よくある質問
Q1. RTX 4090(24GB VRAM)で動かせますか?
Q4_K_M量子化でも87GBあるため、単体では動きません。複数GPU(NVLink接続)か、Mac Studioの192GB統合メモリ、またはクラウド実行(ollama run nemotron-3-super:cloud)が現実的な選択肢です。
Q2. DeepSeek-R1とどちらが賢いですか?
タスクによります。数学推論(HMMT 94.73)とエージェント性能(PinchBench 85.6%)ではNemotron-3-Superが強く、汎用的なチャット品質ではDeepSeek-R1に分があります。DeepSeek-R1はDeepSeek-V3(671B/37BアクティブのMoE)をベースに強化学習で推論能力を鍛えたモデルで、アーキテクチャの方向性が異なります。Nemotronはエージェント性能と長文脈に特化、DeepSeek-R1は深い思考チェーンに特化しています。
Q3. 日本語の性能はどうですか?
対応7言語に日本語が含まれ、MMLU-ProX(多言語版MMLU-Pro)で79.35を記録しています。ただし、日本語単独のベンチマーク(JMT-Bench等)の公式スコアは公開されていません。実用的な日本語能力の評価は、実際に試す必要があります。
Q4. 商用利用は可能ですか?
はい。NVIDIA Nemotron Open Model Licenseの下で商用利用が許可されています。
Q5. Reasoning機能はどう切り替えますか?
チャットテンプレートのフラグで切り替え可能です。NVIDIA API経由の場合はreasoning_effortパラメータで"none"(推論なし)、"low"、"high"を指定します。推論バジェットは最大32,768トークンです。NVIDIA APIではデフォルトでtemperature: 1.0、top_p: 0.95が設定されています。
Q6. Nemotron-3-Ultraはいつ出ますか?
NVIDIAは「2026年前半」と発表しています。Ultraはファミリー内の最高性能モデルで、ミッションクリティカルなマルチステップワークフロー向けとされていますが、詳細なスペックはまだ公開されていません。
まとめ
Nemotron-3-Superは、「120Bの知識を12Bのコストで」というMoEの本質的な価値を、Mamba-2とLatentMoEの組み合わせで極限まで追求したモデルです。
数学推論94.73、エージェント性能85.6%、100万トークンのコンテキスト、NVFP4でも劣化しない精度──技術的な完成度は文句なしに高い。一方で、87GBという現実的なVRAM要件は「ローカルLLM」の文脈では依然として壁です。
個人開発者はollama run nemotron-3-super:cloudでまず性能を体験し、本番導入はNVIDIA GPU環境の構築とセットで検討するのが合理的でしょう。マルチエージェントシステムを企業で構築する開発チームにとっては、2026年3月時点で最も検討に値するオープンMoEモデルです。
関連記事: