
Gemini Embedding 2 完全ガイド【2026年3月】|Googleが放つ初のマルチモーダル埋め込みモデルの全貌
2026年3月10日、GoogleはGemini Embedding 2を発表しました。テキスト、画像、動画、音声、PDFの5つのモダリティを1つのベクトル空間にマッピングできる、初のネイティブマルチモーダル埋め込みモデルです。これまで「テキストはテキスト用モデル、画像は画像用モデル」と分けて処理していた世界が、1つのモデルで完結する時代に入りました。
本記事では、Gemini Embedding 2の技術仕様・ベンチマーク・料金・実装方法から競合比較まで、開発者が知るべきすべてを解説します。
最終更新: 2026年3月12日
Gemini Embedding 2とは何か
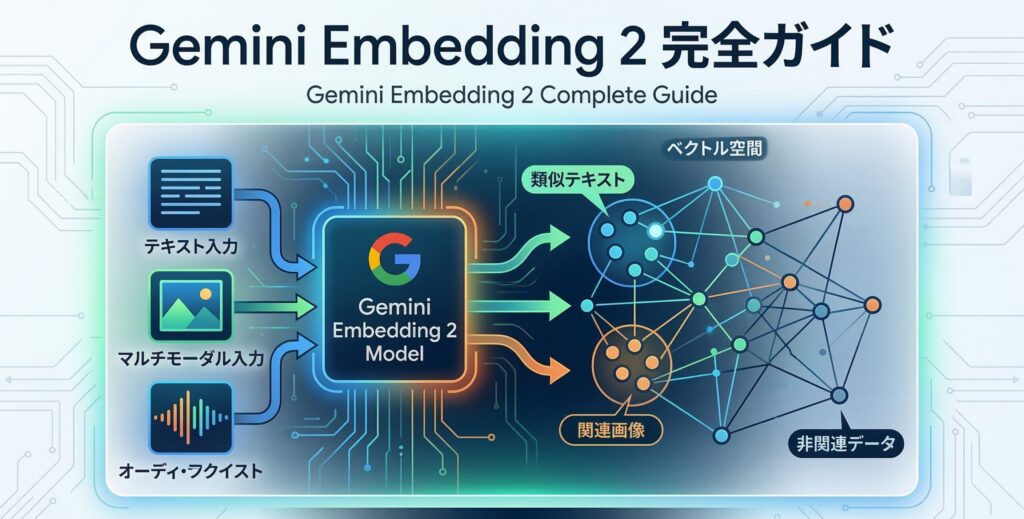
Gemini Embedding 2は、GoogleがGeminiアーキテクチャをベースに構築した初のネイティブマルチモーダル埋め込みモデルです。モデルIDはgemini-embedding-2-previewで、Gemini APIおよびVertex AIからパブリックプレビューとして利用できます。
従来のGoogleの埋め込みモデル(text-embedding-004やgemini-embedding-001)はテキスト専用でした。Gemini Embedding 2は、テキスト・画像・動画・音声・PDFの5種類の入力を受け付け、それらを同一のベクトル空間に変換します。これにより「動画の内容に最も近い記事を検索する」「音声の質問に対して関連する画像を返す」といった、従来は複数のモデルとパイプラインが必要だった処理が1回のAPI呼び出しで実現できます。
技術的な背景として、2025年3月にarXiv論文(2503.07891)「Gemini Embedding: Generalizable Embeddings from Gemini」がJinhyuk Leeら46名の共著で公開されています。この論文はGemini LLMの多言語・コード理解能力を埋め込みタスクに転用するアプローチの基礎研究であり、今回のGemini Embedding 2はその成果をマルチモーダル対応に拡張したモデルです。
なぜマルチモーダル埋め込みが革命的なのか
埋め込み(Embedding)とは、テキストや画像などのデータを数値のベクトル(数百〜数千個の数値の配列)に変換する技術です。意味が近いデータは近いベクトルになるため、「似ている情報を探す」あらゆるタスクの基盤になります。
これまでの課題を具体的に見てみましょう。
従来のアプローチ(モダリティごとに別モデル):
- テキスト → テキスト埋め込みモデル → ベクトルA空間
- 画像 → 画像埋め込みモデル → ベクトルB空間
- 動画 → 動画の説明文をLLMで生成 → テキスト埋め込み → ベクトルA空間
問題はベクトル空間AとBが別の世界だということです。テキストで「夕焼けの海」と検索しても、夕焼けの海の写真のベクトルとは直接比較できません。CLIPのようなモデルでブリッジする手もありますが、精度やコストに課題がありました。
Gemini Embedding 2のアプローチ(統一ベクトル空間):
- テキスト → Gemini Embedding 2 → ベクトル空間X
- 画像 → Gemini Embedding 2 → 同じベクトル空間X
- 動画 → Gemini Embedding 2 → 同じベクトル空間X
- 音声 → Gemini Embedding 2 → 同じベクトル空間X
すべてが同一空間に存在するため、モダリティをまたいだ類似検索がコサイン類似度の計算一発で完了します。パイプラインの複雑さが劇的に減り、精度も向上します。
5つのモダリティ──何をどこまで処理できるのか
Gemini Embedding 2が受け付ける入力タイプと、それぞれの制限値を整理します。
| モダリティ | 上限 | 対応フォーマット | 前モデル比 |
|---|---|---|---|
| テキスト | 最大8,192トークン | プレーンテキスト | 4倍(001は2,048) |
| 画像 | 1リクエストあたり最大6枚 | PNG, JPEG | 新機能 |
| 動画 | 最大128秒 | MP4, MOV(H264, H265, AV1, VP9) | 新機能 |
| 音声 | 最大80秒 | MP3, WAV | 新機能 |
| 最大6ページ | 新機能 |
特に注目すべきは音声のネイティブ対応です。従来は音声ファイルをWhisper等で文字起こしし、そのテキストを埋め込みモデルに通すという2段階のパイプラインが必要でした。Gemini Embedding 2は音声を直接ベクトルに変換するため、文字起こしの精度ロスやレイテンシがなくなります。ポッドキャストの内容検索や、コールセンターの録音から類似ケースを検索するといったユースケースが大幅にシンプルになります。
また、PDF対応により、テキスト+図表+レイアウトを含むドキュメントの意味をそのまま捉えられます。研究論文、契約書、マニュアルなど、構造化されたドキュメントのセマンティック検索に特に有効です。
テキストの入力上限は8,192トークンで、前モデル(gemini-embedding-001の2,048トークン)の4倍です。長い技術文書やコードファイルを分割せずにそのまま埋め込めるケースが増え、チャンキング戦略の設計負荷が大幅に軽減されます。
なお、100以上の言語をサポートしています。日本語はもちろん、多言語コンテンツを扱うグローバルサービスでの活用にも適しています。
マトリョーシカ表現学習──次元数を自在に操る
Gemini Embedding 2はマトリョーシカ表現学習(Matryoshka Representation Learning / MRL)を採用しています。ロシアの入れ子人形(マトリョーシカ)にちなんだこの技術は、ベクトルの最初の方の次元に最も重要な情報を集約するようにモデルを訓練するものです。
これにより、デフォルトの3,072次元から任意のサイズにベクトルを切り詰めても、品質の低下が最小限に抑えられます。
Googleが推奨する次元数は3パターンあり、それぞれに適したユースケースがあります:
- 3,072次元(デフォルト):最高精度。法律文書、医療データ、複雑な技術文書など、検索の正確性が最重要なケース
- 1,536次元:精度とストレージのバランス型。一般的なRAGシステムやセマンティック検索に最適
- 768次元:低レイテンシ・省メモリ型。リアルタイム検索や大規模データセットでのコスト最適化に
実際のベンチマークでは、768次元に切り詰めても1,536次元と比べてMTEBスコアの差はわずか0.18ポイント(67.99 vs 68.17)です。ストレージは半分になるのに、品質はほぼ維持される。これがMRLの威力です。
APIでの次元数指定はoutput_dimensionalityパラメータで簡単に切り替えられます。128〜3,072の範囲で指定可能ですが、3,072以外の次元数を使う場合はベクトルの正規化(Normalization)が必要な点に注意してください。
8つのタスクタイプ──用途別に最適化する方法
Gemini Embedding 2は、埋め込み生成時にタスクタイプを指定することで、そのユースケースに最適化されたベクトルを返します。公式ドキュメントでは以下の8つが定義されています。
- SEMANTIC_SIMILARITY:2つのテキストの意味的な類似度を評価
- CLASSIFICATION:事前定義されたラベルにテキストを分類
- CLUSTERING:類似性に基づいてテキストをグループ化
- RETRIEVAL_DOCUMENT:ドキュメント検索用(インデックス側)
- RETRIEVAL_QUERY:検索クエリ用(クエリ側)
- CODE_RETRIEVAL_QUERY:自然言語からコードブロックを検索
- QUESTION_ANSWERING:質問応答システムの質問側
- FACT_VERIFICATION:事実検証が必要な文の埋め込み
なぜタスクタイプの指定が重要なのか?同じ文章でも、「検索クエリとして使う」のと「検索対象のドキュメントとして使う」のではベクトルの最適な形が異なります。たとえばRAGシステムでは、ドキュメントのインデックス作成時にはRETRIEVAL_DOCUMENT、ユーザーの質問処理時にはRETRIEVAL_QUERYを指定します。これだけで検索精度が体感できるレベルで向上します。
CODE_RETRIEVAL_QUERYは、自然言語で「エラーハンドリングのパターン」と入力すると、該当するコードブロックを返すようなユースケースに最適化されています。コードベース検索やドキュメント検索を構築する開発者には特に有用です。
ベンチマーク──MTEBスコアと競合との位置関係
埋め込みモデルの性能評価で最も広く使われるのがMTEB(Massive Text Embedding Benchmark)です。Gemini Embedding 2のスコアを整理します。
| ベンチマーク | スコア | 備考 |
|---|---|---|
| MTEB(2,048次元) | 68.16 | 高次元での高精度スコア |
| MTEB(1,536次元) | 68.17 | 2,048次元とほぼ同等 |
| MTEB(768次元) | 67.99 | 1/4の次元数でも−0.18のみ |
| MTEB Multilingual | 69.9 | 多言語リーダーボード1位 |
| MTEB Code | 84.0 | コード検索・理解タスクで圧倒的スコア |
注目すべきはMTEB Multilingual(69.9)とMTEB Code(84.0)の高さです(TokenCost調べ)。多言語リーダーボードでは1位を獲得しており、100以上の言語にまたがるタスクでの汎用性が証明されています。コードベンチマークの84.0は、コード検索や技術文書の検索を構築する開発者にとって非常に心強い数字です。
ただし、公平に見る必要がある点もあります。2026年3月時点のMTEBリーダーボードでは、NVIDIAのNV-Embed-v2(72.31)やQwen3-Embedding-8B(70.58)がMTEB全体の平均スコアではGeminiを上回っています。ただしこれらはレガシーMTEB(56タスク)での評価であり、評価基準が異なる点は留意が必要です。Gemini Embedding 2の強みはRetrieval(検索)タスクでの精度とマルチモーダル対応の組み合わせにあり、RAGシステムを構築する実務では最も重要な指標です。
料金──テキスト100万トークン約30円から
Gemini API公式料金ページ(2026年3月時点)に基づく料金を整理します。
| 入力タイプ | 100万トークンあたり | 単位あたり | 無料枠 |
|---|---|---|---|
| テキスト | $0.20(約30円) | ─ | あり |
| 画像 | $0.45(約68円) | 約$0.00012/枚 | あり |
| 音声 | $6.50(約975円) | 約$0.00016/秒 | あり |
| 動画 | $12.00(約1,800円) | 約$0.00079/フレーム | あり |
| gemini-embedding-001(テキスト専用・参考) | $0.15(約23円) | ─ | あり |
※日本円は記事執筆時点(2026年3月・1ドル≒150円)の参考換算額です
すべての入力タイプに無料枠が存在します。開発・検証段階ではコストゼロで試せるのは大きなメリットです。
テキスト埋め込みの$0.20/100万トークンは、たとえば1,000文字の日本語テキスト(約500トークン)を100万件処理しても約$100(約15,000円)です。多くのRAGシステムで十分に実用的な価格帯と言えます。
なお、gemini-embedding-001にはバッチAPI(50%割引の$0.075/100万トークン)が利用できますが、gemini-embedding-2-previewのバッチAPIは2026年3月時点で未提供です。大規模なバッチ処理が主要ユースケースの場合は、正式リリースまでgemini-embedding-001の併用を検討してください。
競合比較──OpenAI・Cohere・Voyage AIとの違い
Gemini Embedding 2の最大の差別化ポイントは「ネイティブマルチモーダル」ですが、テキスト埋め込みだけで比較した場合はどうでしょうか。主要な競合モデルとスペック・料金を比較します。
| モデル | 料金/100万トークン | 最大入力 | 最大次元数 | マルチモーダル | MRL対応 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 8,192 | 3,072 | ✓ 5種類 | ✓ |
| OpenAI text-embedding-3-large | $0.13 | 8,191 | 3,072 | ✗ テキストのみ | ✓ |
| OpenAI text-embedding-3-small | $0.02 | 8,191 | 1,536 | ✗ テキストのみ | ✓ |
| Cohere Embed v4 | $0.10 | 128,000 | 1,024 | ✗ テキストのみ | ─ |
| Voyage AI voyage-3-large | $0.18 | 32,000 | 1,024 | ✗ テキストのみ | ─ |
テキストのみの用途でコスト最優先なら、OpenAI text-embedding-3-smallの$0.02/100万トークンが圧倒的に安い。これはGemini Embedding 2の10分の1の価格です。テキスト検索だけで十分なシステムには正直こちらの方がコスパは良いでしょう。
Gemini Embedding 2を選ぶべきケースは明確です:
- 画像・動画・音声・PDFを含むデータソースを統一的に検索したい
- 多言語対応が重要(MTEB Multilingualで1位)
- コード検索の精度を重視(MTEB Code 84.0)
- Google Cloud / Vertex AIのエコシステムを既に使っている
逆に、テキストのみ・英語中心・コスト重視なら、OpenAIやCohereが有力な選択肢です。ツールは用途で選ぶもの。万能モデルが常に最適解ではありません。
実践ユースケース──RAG・セマンティック検索・クロスモーダル推薦
Gemini Embedding 2のマルチモーダル機能が特に威力を発揮するユースケースを3つ紹介します。
1. マルチモーダルRAG(Retrieval-Augmented Generation)
従来のRAGは「テキスト文書を検索してLLMに渡す」構成でした。Gemini Embedding 2を使えば、テキスト・画像・動画・PDFを含むナレッジベースに対して、ユーザーの質問(テキスト)からモダリティを問わず関連情報を検索できます。
たとえば製造業の保守マニュアルシステムで「ポンプの異音がする」と質問すると、テキストの手順書だけでなく、関連する修理動画や部品図面(PDF)も同時にヒットする。これがマルチモーダルRAGの威力です。
2. 音声ネイティブのセマンティック検索
コールセンターの録音データ、ポッドキャストのエピソード、会議の録音。これらの音声データを文字起こしなしで直接埋め込み、類似ケースを検索できます。文字起こしの精度ロス(方言、専門用語、ノイズ)を回避でき、トーンや感情のニュアンスも捉えられる可能性があります。
3. クロスモーダル推薦システム
ECサイトで「ユーザーが閲覧した商品画像に最も近い説明文の商品」を推薦する、あるいは動画プラットフォームで「この動画を見た人が読みたい記事」を提案する。従来はメタデータやタグに頼っていた異種モダリティ間の推薦が、ベクトルの近傍検索だけで実現できます。
実装ガイド──Gemini APIで今すぐ始める
Gemini Embedding 2はGemini APIとVertex AIの両方で利用可能です。ここではGemini APIを使ったPythonの実装例を紹介します。
テキスト埋め込みの基本:
from google import genai
client = genai.Client()
# テキスト埋め込み(検索クエリ用)
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents="量子コンピュータの現在の課題は何か",
config={
"task_type": "RETRIEVAL_QUERY",
"output_dimensionality": 768 # MRLで次元数を指定
}
)
print(f"次元数: {len(result.embeddings[0].values)}") # 768画像の埋め込み:
from google import genai
from google.genai import types
client = genai.Client()
# ローカル画像ファイルを埋め込み
with open("product_photo.jpg", "rb") as f:
image_data = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=types.Part.from_bytes(
data=image_data,
mime_type="image/jpeg"
)
)
# テキストと同じベクトル空間 → コサイン類似度で比較可能マルチモーダル検索の流れ:
# 1. インデックス構築(ドキュメント・画像・動画を同一空間に埋め込み)
docs = embed(texts, task_type="RETRIEVAL_DOCUMENT")
imgs = embed(images) # 画像も同じ空間
vids = embed(videos) # 動画も同じ空間
# 2. 全ベクトルをベクトルDBに格納(Pinecone, ChromaDB, Weaviate等)
index.upsert(docs + imgs + vids)
# 3. テキストクエリで検索 → モダリティを問わず類似結果が返る
query_vec = embed("夕焼けの海", task_type="RETRIEVAL_QUERY")
results = index.query(query_vec, top_k=10)
# → 海の夕焼けの写真も、関連する動画も、テキスト記事もヒットする対応する統合ライブラリとして、LangChain、LlamaIndex、Weaviate、Qdrant、ChromaDB、Pineconeが公式に対応しています。CrewAIやVercel AI SDKも統合パートナーに含まれています。既存のRAGパイプラインへの組み込みも比較的容易です。
筆者の分析──Gemini Embedding 2は「静かな革命」である
ここからはスペックを離れて、Gemini Embedding 2が埋め込みモデル市場と開発者の実務にどういう影響を与えるか、独自の分析を述べます。
なぜGoogleは「埋め込み」に本気を出したのか
Gemini Embedding 2の発表は、一見するとGemini 2.5のような派手なモデルリリースに隠れがちです。しかし戦略的には極めて重要な一手だと考えます。
理由は単純で、埋め込みモデルはRAGパイプラインの「入り口」だからです。RAGシステムを構築する開発者は、まず埋め込みモデルを選び、そのベクトルDBを中心にアーキテクチャを組む。一度選んだ埋め込みモデルを後から変えるのは、全データの再埋め込みが必要なため非常にコストが高い。つまり埋め込みモデルの選択はロックインに直結する。
GoogleがVertex AIとGemini APIの両方で提供し、無料枠を全モダリティに設定し、LangChain/LlamaIndex等のエコシステム統合を初日から用意しているのは、「まず埋め込みで入ってもらい、その後Gemini LLMでの生成、Vertex AIでの本番運用へと繋げる」という明確なファネル戦略です。
「マルチモーダル埋め込み」は本当に必要なのか──冷静な評価
正直に言えば、2026年3月時点で大半のRAGシステムはテキスト検索だけで十分に機能しています。画像や動画を含むナレッジベースを検索する需要は確かにありますが、実際に本番で使っている企業はまだ少数派です。
しかし、これは「スマートフォンが出た当初、多くの人が『電話とメールだけでいい』と言っていた」のと似ています。マルチモーダル埋め込みの真価は、今は存在しないユースケースを可能にするところにあります。
具体的に予測すると:
- 6ヶ月以内:製造業・医療・不動産など、画像+テキストの混在データを持つ業界で先行事例が出始める
- 1年以内:動画プラットフォームや教育サービスで、動画コンテンツのセマンティック検索が標準機能になる
- 2年以内:マルチモーダル検索は「当たり前」になり、テキストのみの検索が「レガシー」と見なされるようになる
音声ネイティブ対応──最も過小評価されている機能
5つのモダリティの中で、筆者が最も大きなインパクトを持つと考えるのは音声のネイティブ対応です。
その理由は、音声データは「処理したいのにコストが高すぎて放置されている」データの代表格だからです。コールセンターの録音、営業の商談録音、社内会議の記録──これらは膨大に蓄積されているのに、文字起こし→テキスト検索という2段階の処理が面倒で、ほとんどの企業がアクティブに活用できていません。
Gemini Embedding 2の音声ネイティブ対応は、この「死蔵データ」を一気に検索可能にする可能性があります。特に日本語の音声は、文字起こし精度が英語に比べてまだ低いため、文字起こしを介さない直接埋め込みのメリットは日本市場でこそ大きいと考えます。
OpenAIとの競争──勝つのはどちらか
テキスト埋め込みのコスト面ではOpenAIが圧倒的に優位です(text-embedding-3-small: $0.02 vs Gemini: $0.20)。しかしOpenAIは2026年3月時点でマルチモーダル埋め込みモデルを提供していません。
筆者の見立てでは、OpenAIが半年以内にマルチモーダル埋め込みモデルを出す可能性は高い。GPT-4oのマルチモーダル能力を考えれば技術的な障壁は低いはずです。競争が起きれば価格は下がり、開発者にとっては良いことしかありません。
重要なのは、今の時点で「埋め込みモデルをどう選ぶか」のフレームワークを持っておくことです。マルチモーダルが必要か?多言語対応は?コード検索は?バッチ処理のボリュームは?──これらの軸で評価すれば、プロバイダーが増えても冷静に判断できます。
結論:「今すぐ全面移行」ではなく「今すぐ検証」が正解
Gemini Embedding 2はパブリックプレビュー段階です。GAリリースまでにベクトル空間が変更される可能性もゼロではない。本番環境の全面移行は時期尚早です。
しかし、無料枠を使って自社データでの精度検証は今すぐやるべきです。特にマルチモーダルデータ(画像+テキスト、音声+テキスト)を持つ企業は、従来のテキスト検索との精度差を自分の目で確認してください。数値で語れる検証結果があれば、GAリリース時に即座に移行判断ができます。
移行の注意点──embedding-001との互換性
既にGoogleの埋め込みモデルを使っている開発者にとって最も重要な注意点があります。
⚠️ 重要:ベクトル空間の非互換性
gemini-embedding-001とgemini-embedding-2-previewの埋め込み空間は互換性がありません。モデルを切り替える場合、既存のすべてのデータを新モデルで再埋め込みする必要があります。
これはtext-embedding-004やtext-multilingual-embedding-002からの移行も同様です。異なるモデルで生成されたベクトル同士のコサイン類似度は意味を持ちません。
移行の推奨手順:
- 新モデルで全データを再埋め込み(バッチ処理で並列実行推奨)
- 新旧のインデックスを並行稼働(Blue/Greenデプロイ)
- 検索品質をA/Bテストで比較検証
- 問題なければ旧インデックスを廃止
大規模データセットの再埋め込みにはコストと時間がかかります。現時点ではGemini Embedding 2はパブリックプレビューであり、正式リリース(GA)までにベクトル空間が変更される可能性もゼロではありません。本番環境への全面移行はGAを待ってから判断するのが無難です。
よくある質問
Q1. Gemini Embedding 2は無料で試せますか?
はい。テキスト・画像・音声・動画のすべての入力タイプに無料枠があります。Gemini API公式料金ページで最新の無料枠を確認してください。
Q2. gemini-embedding-001とどちらを使うべきですか?
テキストのみの用途で、バッチAPI(50%割引)を活用したい場合はgemini-embedding-001がコスト効率に優れます。マルチモーダル対応が必要、または8,192トークンの長文対応が必要な場合はgemini-embedding-2-previewを選択してください。
Q3. OpenAIの埋め込みモデルからの移行は簡単ですか?
API呼び出しの形式は異なりますが、LangChainやLlamaIndex経由で利用すればプロバイダーの切り替えは数行の変更で済みます。ただし、ベクトル空間が異なるため全データの再埋め込みは必須です。
Q4. 日本語の精度はどうですか?
MTEB Multilingualベンチマークで1位を獲得しており、100以上の言語での汎用性が実証されています。日本語を含む多言語環境での利用に適しています。
Q5. 「パブリックプレビュー」とは本番環境で使っていいという意味ですか?
パブリックプレビューは一般利用可能だが正式リリース(GA)前の段階です。本番利用は可能ですが、APIの仕様変更やベクトル空間の変更が起こる可能性があります。ミッションクリティカルなシステムではGAを待つことを推奨します。
Q6. Vertex AIとGemini APIの違いは何ですか?
Gemini APIはGoogle AI Studioから直接利用するシンプルな方式です。Vertex AIはGoogle Cloudのフルマネージド環境で、VPC Service Controls、IAM統合、監査ログなどエンタープライズ機能が利用できます。セキュリティ要件が厳格な企業にはVertex AIを推奨します。
まとめ
Gemini Embedding 2は、テキスト・画像・動画・音声・PDFを統一ベクトル空間に変換する初のネイティブマルチモーダル埋め込みモデルです。「別々のモデルで別々のベクトル空間を管理する」というこれまでの常識を覆す、アーキテクチャレベルのパラダイムシフトと言えます。
Gemini Embedding 2を選ぶ理由:
- 5つのモダリティを1つのAPIで処理(パイプラインの大幅簡素化)
- 8,192トークン対応(前モデルの4倍、チャンキング負荷の軽減)
- MRLによる柔軟な次元数選択(768次元でもほぼ同等の品質)
- MTEB Multilingual 1位、MTEB Code 84.0の高い汎用性
- 無料枠があり、すぐに試せる
注意すべき点:
- テキストのみならOpenAIの方が安い選択肢がある
- バッチAPIは未提供(2026年3月時点)
- パブリックプレビュー段階(GA前の仕様変更リスク)
- 旧モデルとのベクトル空間非互換(移行時に全データ再埋め込みが必要)
マルチモーダルRAGやクロスモーダル検索を構築する開発者にとって、Gemini Embedding 2は現時点で最も有力な選択肢です。まずは無料枠で自分のデータセットを試してみてください。
関連記事
最終更新: 2026年3月12日