
2025年、「バイブコーディング」という言葉がソフトウェア開発の常識を覆しました。AIに自然言語で指示するだけでコードが生成される。しかし1年後の2026年、その限界が明らかになっています。Stack Overflow 2025調査によると、開発者の84%がAIツールを使用する一方、AIの出力を信頼しているのはわずか29%。この「使っているが信頼していない」というパラドックスを解決する新しいアプローチが、エージェンティックエンジニアリングです。
本記事では、Andrej Karpathyが提唱したこの概念の定義から、実践テンプレート、失敗パターン、セキュリティ対策、エンタープライズ導入事例まで、日本語で最も包括的なガイドをお届けします。
目次
- エージェンティックエンジニアリングとは
- スペクトラム:Vibe Codingから完全自律までの5段階
- 数字で見る2026年のAI開発
- Context Engineering:AIの「記憶」を設計する技術
- CLAUDE.md / .cursorrules 実践テンプレート
- ADLC:AIネイティブな開発ライフサイクル
- Addy Osmaniの4ステップワークフロー
- 失敗パターンカタログ:7つのアンチパターン
- 理解負債(Comprehension Debt)という新概念
- セキュリティ:Lethal Trifectaと512件の脆弱性
- ツール比較:エージェンティック開発ツール7選
- エンタープライズ導入:Rakuten事例とGartner予測
- よくある質問(FAQ)
- まとめ:エンジニアが今週やるべき3つのこと
エージェンティックエンジニアリングとは
2026年2月4日、OpenAI共同創設者のAndrej KarpathyがX(旧Twitter)で投稿した一言が、ソフトウェア開発の世界に新しい波を起こしました。「バイブコーディング」の1周年を振り返りつつ、彼はその進化形を定義しました。
“‘agentic’ because the new default is that you are not writing the code directly 99% of the time, you are orchestrating agents who do and acting as oversight — ‘engineering’ to emphasize that there is an art & science and expertise to it.”
— Andrej Karpathy, 2026年2月4日
つまり、エージェンティックエンジニアリングとは「AIエージェントを指揮・監督しながら、ソフトウェアの品質を一切妥協しない開発手法」です。コードの99%はAIが書く。しかし設計判断、品質管理、アーキテクチャの意思決定は人間が担う。バイブコーディングが「雰囲気でAIに任せる」だったのに対し、エージェンティックエンジニアリングは「戦略的にAIを統率する」アプローチです。
IBMの定義によると、エージェンティックエンジニアリングは「エージェントがコードを書き、人間の開発者がその出力を監督・検証する、ヒューマン・イン・ザ・ループのオーケストレーション」です。決定論的なロジックから確率的な判断の領域へシフトするため、組織の思考方法とエンジニアリングチームの運営方法に根本的な変革が必要とされます。
この概念が登場した背景には、AIコーディングツールの急速な進化があります。2023年のGitHub Copilotは行単位の補完ツールでしたが、2024年にはCursorやWindsurfがファイル全体の編集を可能にし、2025年後半からはClaude Code、OpenAI Codex、Gemini CLIなどのエージェンティックなツールが登場しました。これらのツールはファイル作成、テスト実行、Git操作、さらにはWebブラウジングまで自律的に行えます。もはや「AIに手伝ってもらう」のではなく、「AIチームを率いる」時代が到来したのです。
しかし、この急速な進化は新たな問題も生みました。ツールの能力が向上するほど、人間がAIの出力を検証せずに受け入れるリスクが高まります。Stack Overflow 2025調査では、開発者の66%が「AIの回答はほぼ正しいが完全ではない」と回答し、45%が「AI生成コードのデバッグは従来より時間がかかる」と報告しています。エージェンティックエンジニアリングは、まさにこの「80%正しいが20%が問題」という課題に対する体系的な解決策なのです。
| 比較軸 | Vibe Coding | Agentic Engineering | なぜ重要か |
|---|---|---|---|
| 人間の役割 | プロンプトを書いて結果を祈る | アーキテクト兼品質管理者 | 品質の最終責任が明確になる |
| コードレビュー | ざっと目を通す or スキップ | 全差分を理解して承認 | 理解負債を防止する |
| テスト | 「動いたからOK」 | テスト駆動で検証を自動化 | 回帰バグを防ぎスケールする |
| 設計文書 | なし(プロンプトが全て) | CLAUDE.md / AGENTS.md で定義 | AIにコンテキストを与え精度向上 |
| スケーラビリティ | プロトタイプまで | プロダクション品質 | 本番運用に耐える品質を実現 |
| セキュリティ | 考慮なし | 最小権限の原則を適用 | 脆弱性の混入を構造的に防ぐ |
| 対象者 | 非エンジニア・初心者 | プロフェッショナル開発者 | 専門性がAI時代の競争力になる |
表1: Vibe CodingとAgentic Engineeringの比較。Karpathyの目標は「エージェントの活用による生産性向上と、ソフトウェア品質の両立」。
スペクトラム:Vibe Codingから完全自律までの5段階
多くの解説記事が「バイブコーディング vs エージェンティックエンジニアリング」という二項対立で語りますが、現実はもっとグラデーションがあります。自動運転のレベル分けと同様に、AIコーディングにも段階があると考えるべきです。

図1: AI開発の5段階スペクトラム。Level 3「Agentic Engineering」が2026年のスイートスポット。
重要なのは、Level 3(Agentic Engineering)が現時点でのスイートスポットだということです。Level 2のバイブコーディングは生産性を大幅に引き上げますが、テストやセキュリティの観点で本番運用にリスクがあります。Level 4の完全自律は、Devinなどが挑戦していますが、まだ限定的なタスクに留まっています。
Karpathyが強調するのは、Level 3では「エンジニアリング」の部分が非常に重要だという点です。AIエージェントの出力を適切に評価し、アーキテクチャ全体の整合性を保ち、セキュリティやパフォーマンスの要件を満たすためには、従来以上の工学的判断力が必要になります。つまり、AIの台頭によってエンジニアの役割が不要になるのではなく、より高次の判断力が求められるようになったのです。
各レベルは排他的ではありません。プロトタイプにはLevel 2、本番機能開発にはLevel 3、単純なスクリプトにはLevel 1と、タスクの性質に応じて使い分けるのが実践的なアプローチです。
実際の開発現場では、新機能の技術検証(PoC)にはLevel 2のバイブコーディングで素早くプロトタイプを作り、本番実装フェーズに入った段階でLevel 3のエージェンティックエンジニアリングに切り替えるのが効果的です。この使い分けにより、「探索フェーズの速度」と「実装フェーズの品質」の両方を確保できます。重要なのは、自分が今どのレベルで作業しているかを常に意識し、本番コードにLevel 2の「雰囲気」コードが混入しないようにすることです。
数字で見る2026年のAI開発
エージェンティックエンジニアリングの必要性を、データで確認しましょう。2025年から2026年にかけて発表された主要な調査・研究結果をまとめました。
| 指標 | 数値 | 出典 | 前年比・備考 |
|---|---|---|---|
| AIツール利用率 | 84% | SO 2025 | 76%から+8pt |
| AI出力への信頼度 | 29% | SO 2025 | 40%から-11pt(過去最低) |
| Copilotによるタスク完了速度向上 | 55.8% | Peng et al. 2023 | p=0.0017(統計的に有意) |
| AGENTS.mdによる実行時間削減 | 28.6% | arXiv 2601.20404 | 2026年1月発表 |
| AGENTS.mdによるトークン使用量削減 | 16.6% | arXiv 2601.20404 | 1日あたり約45分の節約 |
| 「AIの回答がほぼ正しいが不十分」への不満 | 66% | SO 2025 | 最大の不満要因 |
| AIコードのデバッグが困難 | 45% | SO 2025 | 2番目の不満要因 |
| Gartner: エージェントAI搭載アプリ | 40% | Gartner 2025 | 5%未満から(2026年予測) |
| Gartner: AIプロジェクトのキャンセル率 | 40%超 | Gartner 2025 | 2027年末までの予測 |
表2: AI開発に関する主要統計データ。利用率は上昇し続ける一方、信頼度は低下。このギャップがエージェンティックエンジニアリングの必要性を示している。
ここで注目すべきは、利用率84%と信頼度29%のギャップです。開発者の大多数がAIを使っているにもかかわらず、その出力を信頼しているのは3割未満。66%が「AIの回答はほぼ正しいが完全ではない」と感じています。これはまさに「80%問題」の統計的裏付けです。
一方で、適切なコンテキスト設計(AGENTS.md)を行うだけで実行時間が28.6%短縮されるという研究結果は、エージェンティックエンジニアリングの具体的な効果を示しています。AIの問題はAIそのものではなく、AIに与えるコンテキストの設計にあるのです。
Context Engineering:AIの「記憶」を設計する技術
エージェンティックエンジニアリングの核心技術がContext Engineering(コンテキストエンジニアリング)です。これは、推論時にLLMに渡される全ての情報を設計・管理する技術のことです。
Martin Fowlerのサイトでも取り上げられているように、コンテキストエンジニアリングは「プロンプトエンジニアリング」の次のステップです。プロンプトエンジニアリングが「1つの質問の聞き方を最適化する」のに対し、コンテキストエンジニアリングは「AIがタスクに取り組む前の環境全体を設計する」アプローチです。
具体的に何を設計するのか。AIコーディングエージェントが読み込む主要なファイルは以下の通りです。
CLAUDE.md(Claude Code用)
AnthropicのClaude Codeが起動時に自動的に読み込むメモリファイルです。プロジェクトのルール、コーディング規約、テスト方法、アーキテクチャの方針を記述します。これにより、毎回のプロンプトで繰り返し説明する必要がなくなり、一貫した出力が得られます。
AGENTS.md(クロスツール標準)
2026年1月の研究(arXiv: 2601.20404)によると、AGENTS.mdファイルを配置するだけで、AIエージェントの実行時間が28.6%短縮され、トークン使用量が16.6%削減されました。10リポジトリ・124プルリクエストを対象とした実験で、1日あたり約45分の時間節約に相当します。AGENTS.mdは現在、Linux Foundation傘下のAgentic AI Foundationが標準化を進めています。
GEMINI.md / .cursorrules
Google Gemini CLI用のGEMINI.md、Cursor IDE用の.cursorrules(最新版では.cursor/rules)も、同じ目的を果たすファイルです。ツールごとに名前は異なりますが、「AIにコンテキストを事前に与えて精度を上げる」という哲学は共通しています。
コンテキストエンジニアリングの6つの要素は次の通りです。
- コマンド(Commands): ビルド、テスト、リントの実行方法
- テスト(Testing): テストフレームワーク、カバレッジ要件
- プロジェクト構造(Structure): ディレクトリ構成と各層の責務
- コードスタイル(Style): 命名規約、フォーマット、TypeScript strictモード等
- Gitワークフロー(Git): ブランチ戦略、コミットメッセージ規約
- 境界線(Boundaries): AIが変更してはいけないファイル、環境変数の扱い
これらを適切に定義することで、AIエージェントは「プロジェクトのことを何も知らない新入社員」から「チームの規約を熟知したベテラン」に変貌します。
コンテキストエンジニアリングでよくある失敗は、情報を詰め込みすぎることです。CLAUDE.mdに500行のルールを書いても、AIのコンテキストウィンドウを圧迫するだけで逆効果になります。効果的なCLAUDE.mdは、50〜150行程度に収まっているものが多く、「このプロジェクトで最も重要な10のルール」に絞り込む作業自体が、チームのコーディング哲学を明確にする良い機会になります。また、禁止事項(「〜してはいけない」)よりも推奨事項(「〜の場合は〜を使う」)を中心に書く方が、AIの出力品質が安定する傾向があります。
注意すべきは、コンテキストエンジニアリングは「一度設定して終わり」ではない点です。プロジェクトの成長に合わせてCLAUDE.mdやAGENTS.mdも進化させる必要があります。新しいライブラリを導入したら記述を追加し、廃止されたパターンがあれば削除する。このファイル自体がチームの「生きたドキュメント」であり、コードレビューの対象にすべきです。
また、コンテキストの階層設計も重要です。プロジェクトルートのCLAUDE.mdにはグローバルなルールを、サブディレクトリのCLAUDE.mdにはそのモジュール固有のルールを記述します。たとえば、src/api/CLAUDE.mdにはAPI設計の原則やレスポンスフォーマットを、src/components/CLAUDE.mdにはUIコンポーネントの命名規約やアクセシビリティ要件を定義できます。この階層構造により、AIエージェントは作業中のディレクトリに最適化されたコンテキストを自動的に取得します。
CLAUDE.md / .cursorrules 実践テンプレート
ここでは、すぐに使えるCLAUDE.mdのテンプレートを紹介します。プロジェクトのルートに配置し、チームの規約に合わせてカスタマイズしてください。
# プロジェクト: [プロジェクト名]
## アーキテクチャ
- フレームワーク: Next.js 15 (App Router)
- 言語: TypeScript (strict mode, any禁止)
- スタイル: Tailwind CSS
- データベース: PostgreSQL + Prisma ORM
- テスト: Vitest + Testing Library
## ディレクトリ構成
```
src/
├── app/ # App Routerページ (Server Components優先)
├── components/ # UIコンポーネント
├── lib/ # ユーティリティ・共通ロジック
├── services/ # 外部API連携層
├── handlers/ # ビジネスロジック層
└── schemas/ # Zodバリデーションスキーマ
```
## コマンド
- ビルド: `npm run build`
- テスト: `npm run test`
- 単一テスト: `npm run test -- --grep "テスト名"`
- リント: `npm run lint`
- 型チェック: `npx tsc --noEmit`
## コーディング規約
- 関数はアロー関数で統一
- コンポーネント名はPascalCase
- ファイル名はkebab-case
- Zodで全API入出力をバリデーション
- エラーハンドリングは必ず実装
- console.logは本番コードに含めない
## Gitワークフロー
- コミットメッセージ: Conventional Commits (feat/fix/refactor/docs/test)
- ブランチ: feature/*, fix/*, refactor/*
- PRは1つの機能・修正につき1つ
## テスト方針
- 新機能には必ずテストを追加
- カバレッジ80%以上を維持
- ユニットテスト → 統合テスト → E2Eの優先順位
## セキュリティ
- APIキーは.env管理 (ハードコード禁止)
- ユーザー入力は必ずサニタイズ
- SQLインジェクション・XSS・CSRF対策必須
## 禁止事項
- any型の使用
- eslint-disableコメント
- テストなしのマージ
- .envファイルのコミットこのテンプレートの各セクションは、前述の6つのコンテキスト要素に対応しています。チームのプロジェクトに合わせて、フレームワーク名やディレクトリ構成を書き換えてください。
| ファイル名 | 対応ツール | 配置場所 | 特徴 |
|---|---|---|---|
| CLAUDE.md | Claude Code | プロジェクトルート | セッション開始時に自動読み込み。階層構造対応(サブディレクトリにも配置可) |
| AGENTS.md | クロスツール標準 | プロジェクトルート / サブディレクトリ | Linux Foundation傘下で標準化中。研究で28.6%の効率改善を実証 |
| GEMINI.md | Gemini CLI / Jules | プロジェクトルート | Google系AIツール用。Gemini CLIが自動認識 |
| .cursorrules | Cursor IDE | プロジェクトルート (.cursor/rules推奨) | Cursor固有。最新版では.cursor/rulesディレクトリに移行 |
表3: 主要AI設定ファイルの比較。全て同じ哲学「AIにプロジェクトのコンテキストを事前に与える」に基づいている。
実務上のアドバイスとしては、AGENTS.md + ツール固有ファイルの組み合わせが最も効果的です。AGENTS.mdにチーム共通のルール(アーキテクチャ、テスト方針、Git規約)を記述し、CLAUDE.mdやGEMINI.mdにはそのツール固有の設定(フック、コマンドエイリアスなど)を追加します。
ADLC:AIネイティブな開発ライフサイクル
ソフトウェア開発のライフサイクルは、ウォーターフォール → アジャイル → ADLC と進化してきました。ADLC(Agentic Development Lifecycle)は、GoogleのCasey Westが提唱する「AIネイティブな開発方法論」です。
Westの「Agentic Manifesto」では、アジャイルマニフェストを意識した4つの価値が宣言されています。
- 網羅的な技術要件よりも、人間の意図を — 人間がビジョンとガードレールを定義し、エージェントが「どうやるか」を担当する
- 固定スプリントよりも、継続的フローを — エージェントはリアルタイムでバリデーション済みのインクリメントを出荷する
- 機能の量よりも、アーキテクチャの整合性を — スピードは構造なしでは混乱を生む。モジュール性、セキュリティ、保守性を守る
- 手動見積もりよりも、自動化された検証を — エージェントがセルフテスト、セルフレビュー、セルフコレクションをループで実行
従来のSDLCとの最大の違いは、フィードバックループの速度です。SDLCでは要件定義→設計→実装→テスト→デプロイが数週間〜数ヶ月かかりましたが、ADLCではエージェントがこのサイクルを数分〜数時間で回します。そのため、品質ゲートも自動化されている必要があります。手動レビューだけに頼ると、エージェントの生産速度がボトルネックになり、ADLCの利点が消えてしまいます。CI/CDパイプラインにAI出力専用の品質ゲート(自動テスト、静的解析、セキュリティスキャン)を組み込むことが前提条件です。
ADLCの最も革新的な概念は、「検証(verification)」から「妥当性確認(validation)」へのシフトです。従来の開発では「指示通りに動くか?」を確認しますが、ADLCでは「意図した通りに動くか?」を確認します。この違いは、非決定論的なAIの出力を扱う上で本質的です。
実践面では、ADLCはコードカバレッジの代わりに「評価スイート」を重視します。バージョン管理されたシナリオ、敵対的プロンプト(レッドチーミング)、定性的なスコアリングルーブリックを組み合わせ、AIの出力品質を継続的にモニタリングします。デプロイはカナリアリリースとフェーズドロールアウトが標準です。
重要な点として、ADLCはSDLCを置き換えるのではなく、ラップするものです。既存の開発プロセスの上にAIネイティブなレイヤーを追加する形で、段階的に導入できます。
ADLCの実践的な導入ステップとしては、まず既存のCI/CDパイプラインにAI出力の自動検証を1つ追加することから始めます。たとえば、AIが生成したPRに対して自動テスト実行 + リンターチェック + セキュリティスキャンを必須ゲートにするだけでも、ADLCの「自動化された検証」原則を部分的に実現できます。いきなり全プロセスを変える必要はありません。
Addy Osmaniの4ステップワークフロー
GoogleのエンジニアリングリーダーであるAddy Osmaniは、2026年2月に公開した「Agentic Engineering」記事で、実践的な4ステップワークフローを提示しました。経験豊富なエンジニアがAIエージェントで2倍〜5倍の生産性向上を実現するための具体的手法です。
Step 1: Plan(計画を立てる)
AIにコードを書かせる前に、設計ドキュメントを作成する。これがエージェンティックエンジニアリングとバイブコーディングの最も大きな違いです。Osmaniは「AIが問題を起こしたのではない。設計思考を省略したことが問題を起こした」と断言しています。
実践プロンプト例:
この機能の設計ドキュメントを作成してください。
要件:
- ユーザー認証にJWTを使用
- リフレッシュトークンをHTTPOnly Cookieに保存
- 失敗時のリトライロジックを含む
まず設計を提示し、承認後にコードを書いてください。Step 2: Direct(指示を出す)
AIエージェントにはスコープを明確に絞ったタスクを与える。「アプリを作って」ではなく、「認証ミドルウェアを作って。JWTの検証とリフレッシュロジックを含め、エラー時はNextResponse.json({ error }, { status: 401 })を返して」のように、具体的に指示します。
Step 3: Test(テストで検証する)
包括的なテストスイートを用意することで、安心してAIに委任できます。テスト駆動開発(TDD)が特に有効で、AIにテストを先に書かせてから実装を生成させると、品質が大幅に向上します。
Step 4: Own(コードベースを所有する)
AIが生成したコードでも、マージしたらあなたのコードです。ドキュメンテーション、バージョン管理、CI/CD、本番監視を維持し、全ての差分を理解してからマージする。「理解できないコードはマージしない」が鉄則です。
Osmaniが指摘する重要なポイントは、成功するエンジニアは時間の70%を問題定義と検証戦略に、30%を実行に使っているということです。従来の開発とは正反対の時間配分であり、これがエージェンティックエンジニアリングの本質を端的に表しています。
このワークフローを実際のプロジェクトに適用する際のコツは、最初の1週間は意識的にStep 1(Plan)に時間をかけることです。多くの開発者がAIの速さに魅了されて「まず書かせてみよう」と飛びつきますが、それはLevel 2のバイブコーディングに逆戻りするパターンです。設計ドキュメントを書く時間は無駄ではなく、AIが生成するコードの品質を根本から引き上げる投資です。設計が明確であればあるほど、AIへの指示も具体的になり、結果として手戻りが激減します。
失敗パターンカタログ:7つのアンチパターン
エージェンティックエンジニアリングの導入で陥りやすい7つのアンチパターンを、症状→原因→対策の形式でカタログ化しました。チームのコードレビューチェックリストとしても活用できます。
1. AI Slop放置
症状: AIが生成した冗長・非効率なコードがそのまま本番に入る。不要なnullチェックの連鎖、過剰な抽象化、意味のないコメントが散在する。
原因: 「AIが書いたから正しいだろう」という過信。レビューの省略。
対策: 全差分を人間がレビューし、AIに「このコードをリファクタリングして。不要な抽象化を削除し、コードを50%簡潔にして」と指示する。
2. Context欠如
症状: AIが既存のアーキテクチャを無視したコードを生成する。同じプロジェクト内でREST APIとGraphQLが混在する、等。
原因: CLAUDE.mdやAGENTS.mdを設定していない。プロジェクトのルールをAIに伝えていない。
対策: Context Engineeringを実装する。最低限、プロジェクト構造・コーディング規約・テスト方針をCLAUDE.mdに定義する。
3. レビュー省略
症状: AIの出力を確認せずにマージ。後から理解できないバグが発生し、デバッグに通常の3倍の時間がかかる。
原因: AIの生産性に酔って「速さ」を「品質」と錯覚している。
対策: Osmaniのワークフロー Step 4「Own」を徹底する。理解できない差分は絶対にマージしない。
4. 過度な自律性
症状: AIエージェントに広範な権限を与えすぎ、意図しないファイル変更やデータ削除が発生する。
原因: 最小権限の原則を適用していない。サンドボックスなしで本番環境にアクセスさせている。
対策: タスクごとにスコープを限定する。ファイル変更は承認制にし、破壊的操作(delete, drop等)には確認を必須にする。
5. テスト無し
症状: AIが生成したコードにテストがない。「動いているから大丈夫」で本番にデプロイし、エッジケースで障害が発生する。
原因: テストをAIへの「追加の指示」として扱い、省略している。
対策: TDDを標準にする。「テストを先に書いて、そのテストをパスする実装を生成して」とAIに指示する。CI/CDでテストを必須ゲートにする。
6. 理解負債の蓄積
症状: コードベースの50%以上をAIが書いたが、チームの誰もその全体像を把握していない。障害時にデバッグできない。
原因: AIの出力速度に人間の理解速度が追いつかない。生成されるままにマージし続けた。
対策: 次のセクションで詳述する「理解負債」への対策を実施する。段階的な導入と、定期的なコード理解セッションを設ける。
7. セキュリティ盲点
症状: AIが生成したコードにSQLインジェクション、XSS、平文パスワード保存などの脆弱性が含まれている。
原因: AIは「動くコード」を優先し、セキュリティはデフォルトでは考慮しない。トレーニングデータに脆弱なコード例が多く含まれている。
対策: CLAUDE.mdにセキュリティ要件を明記する。静的解析ツール(Snyk, Semgrep等)をCI/CDに統合し、AIの出力を自動スキャンする。
これら7つのアンチパターンに共通する根本原因は、「AIの出力をデフォルトで信頼してしまう」という認知バイアスです。人間が書いたコードに対しては自然にレビューの目が厳しくなりますが、AIが生成した「それらしい」コードに対しては警戒心が緩みがちです。エージェンティックエンジニアリングでは、この認知バイアスを仕組みで補正します。自動テスト必須、レビュー必須、セキュリティスキャン必須——人間の判断に頼らず、プロセスで品質を保証するのがプロフェッショナルなアプローチです。
理解負債(Comprehension Debt)という新概念
理解負債(Comprehension Debt)は、AIコーディング時代に生まれた新しいリスク概念です。この用語はJeremy TweiがKarpathyへのリプライで造語し、Addy Osmaniが自身のSubstack記事で詳細に解説したことで広く知られるようになりました。従来の「技術負債」がコード品質の妥協から生まれるのに対し、理解負債は「AIがコードを生成する速度が、人間がそれを理解する速度を超えた時に発生する」ものです。
Osmaniは自身の経験を語っています。「Claudeが数日間先延ばしにしていた機能を実装した。テストはパスした。ざっと見てマージした。3日後、そのコードがどう動いているか説明できなくなった。」これが理解負債の典型的な発生パターンです。
技術負債との違いを整理しましょう。
- 技術負債: コードの品質が低い → 将来の修正コストが増大する
- 理解負債: コードの品質は高いかもしれないが、開発者がそれを理解していない → 障害時にデバッグできない、拡張時に予期しない副作用が生じる
特に危険なのは、AIが生成するコードの「それらしさ」です。変数名は適切で、コメントも付いており、テストも通る。しかしその内部ロジックを開発者が本当に理解しているかは別問題です。
理解負債が危険なのは、蓄積に気づきにくい点です。技術負債はリンターやコードレビューで発見できますが、理解負債は「チームが何を理解していないか」を測定する手段がないからです。障害が発生して初めて露呈し、その時にはデバッグ能力が大幅に低下しています。
対策として、Osmaniは以下を提案しています。
- 「読んでからマージ」の徹底: AIの出力を行単位で読み、理解できない部分はAIに説明させる
- 段階的な委任: 最初は小さなタスクからAIに任せ、徐々にスコープを広げる
- コード理解セッション: 週次でチームメンバーがAI生成コードを解説し合う
- 70/30ルール: 時間の70%を問題定義と検証に、30%を実行に配分する
エージェンティックエンジニアリングにおいて、最も価値のあるスキルは「AIに何を書かせるか判断する力」と「AIの出力を正しく評価する力」です。コードを書く速度が問題ではなく、コードを理解する深度が問題なのです。
理解負債を定量的に測定する方法はまだ確立されていませんが、実践的な指標として「コード説明テスト」が有効です。チームメンバーにAI生成コードの任意の関数を選ばせ、その動作を口頭で説明できるか確認します。説明できない割合が高い場合、理解負債が蓄積している兆候です。Google、Meta、Stripeなどのテック企業では、AI生成コードに対する社内レビュー基準を従来より厳格にする動きが報告されています。
セキュリティ:Lethal Trifectaと512件の脆弱性
AIエージェントのセキュリティは、エージェンティックエンジニアリングにおいて最も過小評価されているリスクです。2つの事例が、その深刻さを物語っています。
Lethal Trifecta(致命的三重苦)
Simon Willisonが2025年6月に提唱し、Martin FowlerのサイトでKorny Sietsma(ThoughtWorks)が詳細に解説した概念です。以下の3つの能力が組み合わさると、データ窃取の攻撃面が完成します。
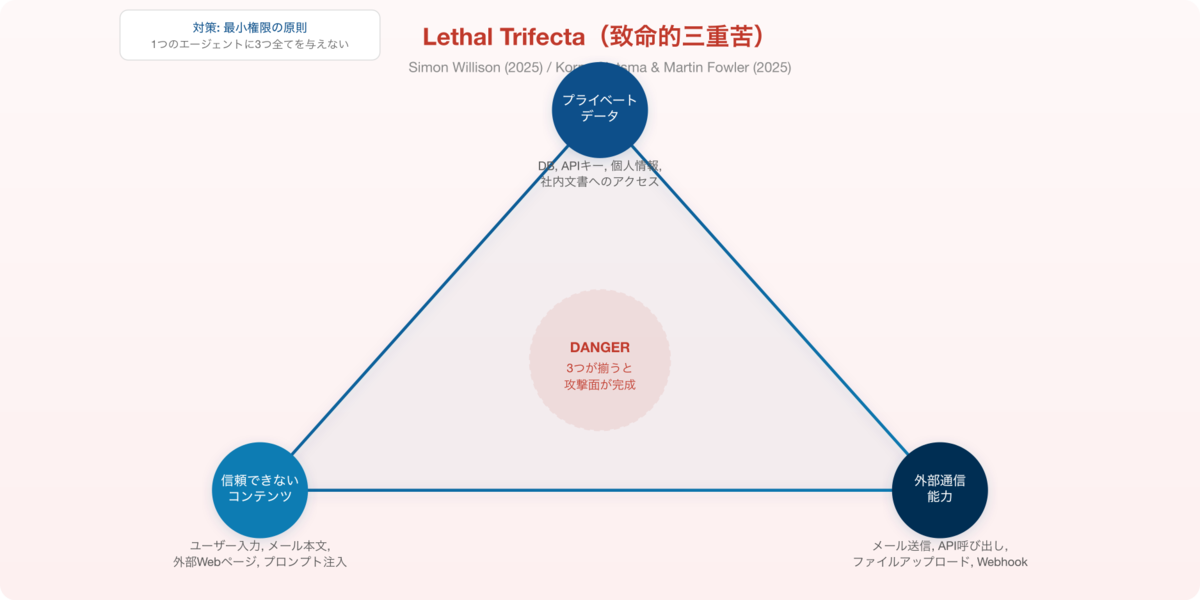
図2: Lethal Trifecta。3つの能力を1つのエージェントに集中させない「最小権限の原則」が対策の基本。
対策は明確です。1つのAIエージェントに3つの能力すべてを与えないこと。タスクを分割し、データアクセスを持つエージェントには外部通信を許可しない、外部コンテンツを処理するエージェントにはプライベートデータへのアクセスを与えない、というように最小権限の原則を適用します。
OpenClaw: 512件の脆弱性
2026年1月、AIエージェントプラットフォーム「OpenClaw」のセキュリティ監査で、512件の脆弱性(うち8件がクリティカル)が発見されました。最も深刻なCVE-2026-25253(CVSS 8.8)は、クロスサイトWebSocket乗っ取りによるワンクリックリモートコード実行を可能にするものでした。
さらに衝撃的なのは、ClawHub(OpenClawのスキルマーケットプレイス)のセキュリティ問題です。Koi Securityの初期監査では2,857件中341件が悪意あるスキルと判定され、その後SnykのToxicSkills調査では3,984件中1,467件(36.8%)にセキュリティ上の問題が検出されました。マーケットプレイスの急拡大に伴い、悪意あるスキルの数は増加し続けています。OAuthの認証情報が平文のJSONファイルに保存されていたことも判明しました。
この事例は、AIエージェントのセキュリティが「あったら良いもの」ではなく「必須要件」であることを証明しています。エージェンティックエンジニアリングでは、以下のセキュリティプラクティスを標準にすべきです。
- 最小権限の原則: エージェントには必要最小限のアクセス権のみ付与
- サンドボックス実行: エージェントをコンテナ内で実行し、ホストシステムを隔離
- 静的解析の自動化: AI生成コードをSnyk、Semgrep等で自動スキャン
- 秘密情報の管理: APIキーや認証情報は環境変数で管理し、コードに含めない
- 監査ログ: エージェントの全操作を記録し、事後分析を可能にする
ツール比較:エージェンティック開発ツール7選
2026年現在、エージェンティックエンジニアリングを実践するための主要ツールを比較します。
| ツール | 提供元 | 動作形態 | 設定ファイル | 自律性 | 料金目安 | 特徴 |
|---|---|---|---|---|---|---|
| Claude Code | Anthropic | ターミナル (CLI) | CLAUDE.md | 高(承認制) | Max 5x: 21,400円/月〜 | マルチファイル編集、Git操作、テスト実行を自律的に実行。承認フローで安全性を確保 |
| OpenAI Codex | OpenAI | クラウド + CLI | AGENTS.md | 高(サンドボックス) | Plus: 3,000円/月〜 | クラウドサンドボックスで安全に実行。複数タスクの並列処理に強い |
| Gemini CLI | ターミナル (CLI) | GEMINI.md | 中〜高 | 無料枠あり | 100万トークンのコンテキストウィンドウ。大規模コードベースの理解に最適 | |
| Cursor | Anysphere | IDE | .cursorrules | 中 | Pro: $20/月 | VS Code fork。エディタ統合型で学習コストが低い。Agent Mode搭載 |
| Windsurf | Codeium | IDE | 独自設定 | 中 | Pro: $15/月 | 「Cascade」による複数ステップのタスク実行。コスパが高い |
| Devin | Cognition AI | クラウド | 独自設定 | 非常に高 | $500/月 | 完全自律型。ブラウザ操作、環境構築も自力で行う。Level 4に最も近い |
| Replit Agent | Replit | ブラウザ IDE | 独自設定 | 高 | Core: $25/月 | セットアップ不要。自然言語からアプリ生成・デプロイまで一気通貫 |
表4: エージェンティック開発ツール7選の比較(2026年3月時点)。料金は変更される場合があります。
これらのツールは急速に進化しており、2025年後半から2026年前半にかけて機能差が縮小する傾向にあります。たとえば、CursorはAgent Modeの導入でCLI型ツールに近い自律性を獲得し、Claude Codeは2026年にVS Code拡張機能を追加してIDE統合も実現しました。選定時には「今どのツールが優れているか」よりも「自分のワークフローにどう組み込むか」を重視すべきです。
ツール選択のポイントは、チームの既存ワークフローとの統合性です。すでにVS Codeを使っているならCursorやWindsurfが導入しやすく、ターミナル中心のワークフローならClaude CodeやGemini CLIが自然です。完全自律を試したいなら Devin、ブラウザ完結ならReplit Agentが適しています。
2026年のトレンドとして注目すべきは、CLI型ツールの台頭です。Claude Code、Codex CLI、Gemini CLIはいずれもターミナルで動作し、既存のGit/CI/CDワークフローとシームレスに統合できます。IDE型ツール(Cursor、Windsurf)がエディタ内の作業を効率化するのに対し、CLI型ツールはファイル操作、テスト実行、Git操作まで含むエンドツーエンドのワークフローを自動化できる点が大きな違いです。特にエージェンティックエンジニアリングの文脈では、CLAUDE.mdやAGENTS.mdとの連携が深いCLI型ツールが優位性を持ちます。
また、複数ツールの併用も現実的な選択肢です。日常的なコーディングにはCursorのAI補完を活用し、複雑な機能実装やリファクタリングにはClaude Codeを起動する。大規模なコードベースの分析にはGemini CLIの100万トークンコンテキストを活用する。1つのツールに固執するのではなく、タスクの性質に応じて最適なツールを選択することが、真のエージェンティックエンジニアリングです。
また、Claude Code vs Codex の詳細比較や、Gemini CLI完全ガイドも合わせてご確認ください。
エンタープライズ導入:Rakuten事例とGartner予測
Rakutenの事例:1,250万行のコードベースでの実証
Anthropicのカスタマーストーリーによると、楽天のMLエンジニア成瀬健太氏は、Claude Codeを使ってvLLM(複数言語で書かれた1,250万行のオープンソースライブラリ)内に、特定のアクティベーションベクトル抽出メソッドを実装しました。
結果は以下の通りです。
- Claude Codeが7時間の自律作業で完了(1回の実行で)
- リファレンスメソッドと比較して99.9%の数値精度
- 新機能のリリースまでの期間が24営業日から5営業日に短縮(79%削減)
この事例が示すのは、エージェンティックエンジニアリングが単なる理論ではなく、エンタープライズ規模で実証されているということです。ただし注意が必要なのは、成瀬氏がMLエンジニアとしての専門知識を持ち、AIの出力を適切に検証できる立場にあったという点です。エージェンティックエンジニアリングの「エンジニアリング」部分が機能したからこそ、この成果が得られました。
楽天の事例から学べる3つの教訓があります。第一に、大規模コードベースこそAIエージェントの価値が高いこと。人間が1,250万行を読み解くには膨大な時間がかかりますが、AIは短時間で関連コードを特定できます。第二に、明確な成功基準(99.9%の数値精度)を事前に定義していたこと。曖昧な「うまくいった」ではなく、定量的な検証が可能だったからこそ、AIの出力を信頼できました。第三に、ドメイン専門家がAIを監督していたこと。AIが書いたコードの正しさを判断できる人間がいなければ、99.9%の精度を確認すること自体が不可能でした。
Gartnerの警告:40%のプロジェクトがキャンセルされる
一方で、Gartnerは2025年6月の予測で厳しい見通しを示しています。
- 2027年末までに40%超のエージェンティックAIプロジェクトがキャンセルされる
- 原因: コスト増大、不明確なビジネス価値、不十分なリスク管理
- 数千のベンダーのうち、本物のエージェンティックAIベンダーはわずか約130社
- 多くのベンダーが「エージェントウォッシング」(既存製品のリブランディング)を行っている
Gartnerのアナリストは、キャンセルの主要因として「スコープクリープ」を指摘しています。初期のPoC(概念実証)では成功を収めたものの、全社展開の段階でコスト・セキュリティ・ガバナンスの問題が顕在化し、ROIが見合わなくなるパターンが典型的です。成功する企業は、最初から「小さく始めて、効果を実証してからスケール」するアプローチを取っています。1つのチーム、1つのプロジェクトでの成功体験を積み重ね、その知見をCLAUDE.mdやAGENTS.mdに蓄積してから横展開する——このインクリメンタルな導入戦略が、40%のキャンセル組に入らないための鍵です。
この「40%導入 × 40%キャンセル」の予測は矛盾ではありません。多くの企業がエージェンティックAIを導入し始めるが、適切なエンジニアリング・プラクティスなしに導入した企業は失敗する、というメッセージです。技術の導入だけでなく、本記事で紹介したContext Engineering、ADLC、セキュリティプラクティスを組み合わせた包括的なアプローチが、成功と失敗を分けます。
よくある質問(FAQ)
Q1. エージェンティックエンジニアリングとバイブコーディングの違いは何ですか?
バイブコーディングは「AIに自然言語で指示し、出力をあまり検証せずに受け入れる」カジュアルなアプローチです。一方、エージェンティックエンジニアリングは「AIエージェントを戦略的に指揮し、設計・テスト・レビューのプロセスを通じて品質を担保する」プロフェッショナルな手法です。Karpathyの言葉を借りれば、「エージェントの活用で生産性を上げつつ、ソフトウェア品質を一切妥協しない」のがエージェンティックエンジニアリングです。
Q2. エージェンティックエンジニアリングに必要なスキルは何ですか?
従来のプログラミングスキルに加え、以下が重要になります。(1) Context Engineering: AIに与えるコンテキストの設計能力、(2) システム設計: AIエージェントのオーケストレーション能力、(3) 検証能力: AIの出力を正しく評価する判断力、(4) セキュリティ意識: AIエージェント固有のリスクへの理解。コードを書く力よりも、コードを読み・評価する力がより重要になります。
Q3. CLAUDE.mdファイルとは何ですか?
CLAUDE.mdは、AnthropicのClaude Codeが起動時に自動的に読み込むプロジェクト設定ファイルです。プロジェクトのアーキテクチャ、コーディング規約、テスト方針、禁止事項などを記述します。これにより、AIが毎回のセッションでプロジェクトのコンテキストを理解した状態でタスクに取り組めます。研究では、類似のファイル(AGENTS.md)の配置で実行時間が28.6%短縮されることが実証されています。
Q4. 理解負債(Comprehension Debt)とは何ですか?
理解負債とは、AIがコードを生成する速度が人間がそれを理解する速度を上回った時に発生する、新しい形の技術的リスクです。コードの品質自体は高くても、開発者がその仕組みを理解していないため、障害時にデバッグできない、拡張時に予期しない問題が生じる、といったリスクが蓄積します。対策は「理解できないコードはマージしない」の徹底と、時間の70%を問題定義と検証に配分することです。
Q5. エージェンティックエンジニアリングのセキュリティリスクとは?
最大のリスクは「Lethal Trifecta」(致命的三重苦)です。AIエージェントが(1)プライベートデータへのアクセス、(2)信頼できないコンテンツへの露出、(3)外部通信能力の3つを同時に持つと、プロンプトインジェクション攻撃によるデータ窃取が可能になります。対策は、1つのエージェントに3つの能力すべてを与えない「最小権限の原則」の適用です。
Q6. エージェンティックエンジニアリングを始めるにはどうすればいいですか?
3つのステップで始められます。(1) 今日: CLAUDE.md(またはAGENTS.md)をプロジェクトルートに作成し、基本的なルールを定義する。(2) 今週: 小さなタスクからAIエージェント(Claude Code等)を試し、Plan→Direct→Test→Ownのワークフローを実践する。(3) 今月: チーム全体のワークフローにContext Engineeringを組み込み、CI/CDにセキュリティスキャンを統合する。
まとめ:エンジニアが今週やるべき3つのこと
エージェンティックエンジニアリングは、AIの「使い方」における根本的なパラダイムシフトです。バイブコーディングが「AIに任せる」だったのに対し、エージェンティックエンジニアリングは「AIを率いる」。この違いが、プロトタイプと本番品質の分水嶺です。
2026年は「AIコーディングツールが一般化した年」ではなく、「AIコーディングの正しい使い方が確立された年」として記憶されるでしょう。Karpathyの定義、Osmaniのワークフロー、Willisonのセキュリティ警告、Westの開発ライフサイクル——これらの知見を統合した体系的アプローチこそが、エージェンティックエンジニアリングです。
本記事で紹介した内容を振り返ると、エージェンティックエンジニアリングの成功には3つの柱が不可欠であることがわかります。第一にContext Engineering(CLAUDE.md/AGENTS.mdによるAIへのコンテキスト設計)、第二に検証プロセス(TDD、全差分レビュー、Plan→Direct→Test→Ownのワークフロー)、第三にセキュリティ意識(Lethal Trifectaへの対策、最小権限の原則)。この3つが揃わないまま「AIにもっと任せよう」と進めると、Gartnerが警告する40%のキャンセル組に入るリスクが高まります。逆に、これらを着実に実装したチームは、楽天のように79%のリリース期間短縮を実現できるポテンシャルがあります。
今週やるべき3つのこと:
- CLAUDE.md(またはAGENTS.md)を作成する — 上記テンプレートをコピーし、プロジェクトのルールを定義する。これだけで実行時間が約30%改善する可能性がある
- Plan→Direct→Test→Ownのワークフローを1つのタスクで試す — 設計を先に書き、スコープを絞った指示を出し、テストで検証し、全差分を理解してからマージする
- Lethal Trifectaをチームで共有する — AIエージェントに与える権限を見直し、最小権限の原則を適用する。セキュリティは後付けでは間に合わない
エージェンティックエンジニアリングの本質は、テクノロジーの問題ではなくマインドセットの問題です。AIを「便利な道具」から「チームの一員」として扱い、その出力に対して人間と同じレベルの品質基準を適用する。AIが99%のコードを書く時代だからこそ、残り1%の判断・設計・検証が、エンジニアの価値そのものになります。
AIコーディングの未来は「人間 vs AI」ではなく、「AIを使いこなすエンジニア vs そうでないエンジニア」の時代です。そして、使いこなすための方法論が本記事で解説したエージェンティックエンジニアリングです。
Karpathyが言うように、「エンジニアリング」を強調するのには理由があります。AIが書くコードの量が増えるほど、人間の設計力・判断力・検証力の価値は上がります。2026年は、その技術を磨く絶好の年です。
参考文献・データソース
- Andrej Karpathy – Agentic Engineering (X, 2026年2月)
- Addy Osmani – Agentic Engineering (2026年2月)
- Addy Osmani – The 80% Problem in Agentic Coding
- Stack Overflow 2025 Developer Survey – AI
- Peng et al. – The Impact of AI on Developer Productivity (arXiv, 2023)
- AGENTS.md Impact Study (arXiv, 2026年1月)
- Casey West – The Agentic Manifesto
- Simon Willison – The Lethal Trifecta (2025年6月)
- Korny Sietsma / Martin Fowler – Agentic AI and Security (2025)
- IBM – What is Agentic Engineering?
- Anthropic – Rakuten Customer Story
- Dark Reading – Critical OpenClaw Vulnerability
- Gartner – 40% Enterprise Apps (2025年8月)
- Gartner – 40% Cancellation Warning (2025年6月)
- Martin Fowler – Context Engineering for Coding Agents
- The New Stack – From Vibes to Engineering