
「ChatGPTに社内データを学習させたい」——この要望を実現する技術がRAG(Retrieval-Augmented Generation)です。
2024年5月には4.0%だった企業のRAG活用率が、同年12月には22.1%に急増(エクサウィザーズ調査)。わずか7ヶ月で5倍以上という成長は、RAGが「実験段階」から「実務導入段階」へ移行したことを示しています。
本記事では、RAGの仕組み・メリット・導入判断のポイントを技術者でなくても理解できるよう徹底解説します。「RAGって何?」という方から「導入を検討中」という方まで、この記事1本でRAGの全体像が把握できます。
RAGとは?3分でわかる基礎知識
RAGの定義
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、AIが回答を生成する際に、外部のデータベースから関連情報を検索(Retrieval)し、その情報を元に回答を生成(Generation)する技術です。
RAG = 検索(Retrieval)+ 生成(Generation)の組み合わせ
「AIに検索エンジンを持たせる技術」とも言えます
なぜRAGが必要なのか?
ChatGPTなどの大規模言語モデル(LLM)には、以下の3つの根本的な限界があります。
❌ 限界1:知識のカットオフ
学習データには期限があり、最新情報を知らない(例:2024年以降の出来事)
❌ 限界2:社内情報へのアクセス不可
御社の製品マニュアル、過去の議事録、顧客データなどは一切知らない
❌ 限界3:ハルシネーション(幻覚)
知らないことも「それらしく」答えてしまい、誤情報を生成するリスク
RAGは、これらの限界を「外部データの参照」によって解決します。
RAGが解決すること
✅ 最新情報への対応
データベースを更新するだけで、AIが最新情報を参照可能に
✅ 社内データの活用
マニュアル、FAQ、過去事例など、自社固有の情報をAIに「教える」
✅ ハルシネーションの抑制
出典を明示した回答が可能になり、「嘘をつく」リスクを大幅に軽減
—
RAGの仕組み:5つのステップで理解する
RAGシステムは、以下の5つのステップで動作します。
Step 1:データの準備(インデックス作成)
社内文書やFAQなどをベクトル化(数値の配列に変換)し、ベクトルデータベースに格納します。これにより「意味的な類似性」で検索が可能になります。
Step 2:ユーザーの質問を受け取る
ユーザーが自然言語で質問を入力します。
「製品Aの返品ポリシーを教えて」
Step 3:関連情報の検索(Retrieval)
質問文もベクトル化し、データベース内で意味的に類似した文書を検索します。キーワード一致ではなく「意味の近さ」で検索するため、表現が違っても関連情報を見つけられます。
Step 4:コンテキストの付与
検索で見つかった関連文書を、ユーザーの質問と一緒にLLMに渡します。
「以下の資料を参考に、ユーザーの質問に答えてください。
【参考資料】製品Aの返品規定:購入後30日以内であれば…
【質問】製品Aの返品ポリシーを教えて」
Step 5:回答の生成(Generation)
LLMが参考資料を踏まえて回答を生成します。出典を明示することで、ユーザーは回答の根拠を確認できます。
質問 → 検索 → 関連情報取得 → LLMに渡す → 回答生成
この流れがRAGの基本アーキテクチャです
—
RAGの6つのメリット
メリット1:最新情報への即座対応
LLMの再学習は膨大なコストと時間がかかりますが、RAGならデータベースを更新するだけで最新情報を反映できます。製品情報の変更、法令改正、新サービスの追加など、ビジネスの変化に即座に対応可能です。
メリット2:ハルシネーションの大幅抑制
RAGは「知っている情報の範囲内」で回答を生成するため、LLM単体と比べて誤情報生成リスクが大幅に低下します。さらに出典を明示できるため、回答の信頼性を検証可能です。
メリット3:セキュリティとプライバシーの確保
社内データを外部のLLMに学習させる(ファインチューニング)場合、情報漏洩リスクが懸念されます。RAGならデータは自社環境に保持したまま、検索結果のみをLLMに渡すため、機密情報の管理が容易です。
メリット4:コスト効率の高さ
LLMのファインチューニングには数百万〜数千万円規模の費用がかかることもありますが、RAGは比較的低コストで導入可能です。
| 項目 | ファインチューニング | RAG |
|---|---|---|
| 初期構築費用 | 数百万〜数千万円 | 数十万〜数百万円 |
| データ更新時 | 再学習が必要 | DB更新のみ |
| 運用コスト | 高い | 比較的低い |
→ 詳細な比較はRAG vs ファインチューニング徹底比較をご覧ください。
メリット5:透明性と説明責任
RAGは回答の根拠となった文書を提示できるため、「なぜその回答になったか」を説明可能です。コンプライアンスが重視される金融・医療・法務などの業界で特に重要な特性です。
メリット6:柔軟なカスタマイズ
部署ごとに参照するデータベースを変えたり、ユーザー権限に応じてアクセス可能な情報を制御したりと、組織の要件に合わせた柔軟な設計が可能です。
—
RAGの活用領域:どんな業務に使える?
RAGは幅広い業務で活用されています。代表的な活用パターンを紹介します。
活用パターン1:社内ナレッジ検索
課題:マニュアルや過去事例が散在し、必要な情報を見つけるのに時間がかかる
RAGの効果:自然言語で質問するだけで、関連情報を要約して回答
導入効果例:情報検索時間を70〜90%削減
活用パターン2:カスタマーサポート
課題:問い合わせ対応に時間がかかり、回答品質にバラつきがある
RAGの効果:FAQや製品情報を参照し、一貫性のある回答を自動生成
導入効果例:対応時間を最大60%短縮(三井住友カード事例)
活用パターン3:ドキュメント作成支援
課題:報告書や稟議書の作成に時間がかかる
RAGの効果:過去の文書を参照し、テンプレートに沿った草案を自動生成
導入効果例:稟議書作成時間を95%削減(宮崎銀行事例)
活用パターン4:専門知識の即時参照
課題:法令、技術仕様、医療情報など専門知識の確認に時間がかかる
RAGの効果:専門文書を参照し、出典付きで正確な情報を提供
導入効果例:法律相談の初期対応をAIが自動化(弁護士ドットコム事例)
—
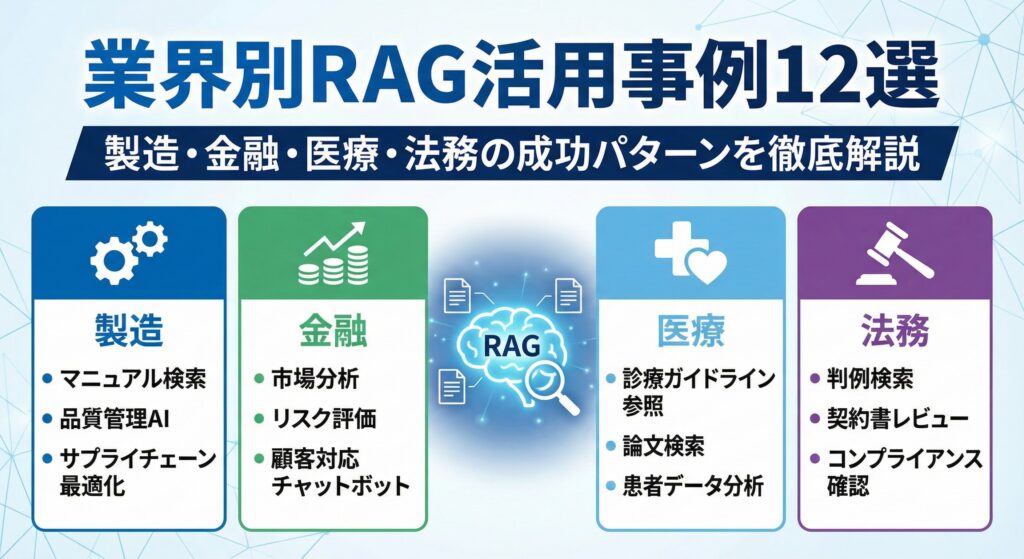
業界別RAG活用事例
RAGは業界を問わず導入が進んでいます。各業界の詳細な活用事例は、以下の専門記事で解説しています。
🏭 製造業
技術継承、トラブルシューティング、マニュアル検索に活用。AGC、中外製薬などの事例。
🏦 金融・銀行
コンプライアンス対応、稟議書作成、リスク管理に活用。三井住友カード、宮崎銀行などの事例。
🏥 医療・ヘルスケア
臨床判断支援、最新論文検索、患者対応に活用。NYU Langone Health、くすりの窓口などの事例。
⚖️ 法務・リーガルテック
契約書検索、判例調査、法律相談対応に活用。LegalOn Cloud、弁護士ドットコムなどの事例。
👥 人事・採用
履歴書スクリーニング、社内規定検索、研修支援に活用。
🏠 不動産
物件検索、契約書レビュー、顧客対応に活用。
🛒 EC・小売
商品レコメンド、カスタマーサポート、在庫管理に活用。
—
RAG導入の費用相場
RAG導入の費用は、規模や要件によって大きく異なります。
| 規模 | 初期構築費用 | 月額運用費用 | 特徴 |
|---|---|---|---|
| スモール (〜1,000文書) |
50〜150万円 | 5〜15万円 | 部門単位での導入 シンプルな構成 |
| ミディアム (1,000〜10,000文書) |
150〜500万円 | 15〜50万円 | 複数部門での利用 権限管理あり |
| ラージ (10,000文書〜) |
500〜2,000万円 | 50〜200万円 | 全社導入 高度なカスタマイズ |
→ 詳細な費用シミュレーションは中小企業向けRAG構築完全ガイドをご覧ください。
—
RAG導入で失敗しないために
RAGは万能ではありません。導入前に以下のポイントを確認しましょう。
よくある失敗パターン
❌ データ品質の軽視
「ゴミを入れればゴミが出る」——元データが整理されていないと、RAGの精度も上がりません。
❌ 過度な期待
RAGを導入しても、すぐに100%正確な回答が得られるわけではありません。継続的なチューニングが必要です。
❌ ユースケースの曖昧さ
「とりあえずRAGを入れてみよう」では失敗します。具体的な業務課題を特定することが重要です。
❌ 運用体制の不備
データの更新、精度のモニタリング、ユーザーフィードバックの収集など、運用フェーズの設計が必要です。
→ 失敗パターンと対策の詳細はRAG導入で失敗する7つの原因をご覧ください。
成功のための5つのステップ
- 課題の明確化:何を解決したいのか、定量的な目標を設定
- データの棚卸し:利用可能なデータの品質・量を確認
- スモールスタート:限定的なユースケースでPoCを実施
- 効果測定:導入前後の業務効率を定量的に比較
- 段階的拡大:成功を確認してから対象範囲を広げる
—
RAGとファインチューニングの使い分け
「RAGとファインチューニング、どちらを選ぶべき?」という質問をよく受けます。結論から言うと、多くのケースでRAGが適切です。
| 判断基準 | RAGが適切 | ファインチューニングが適切 |
|---|---|---|
| データ更新頻度 | 頻繁に更新される | ほぼ固定 |
| 出典の明示 | 必要 | 不要 |
| 予算 | 限られている | 十分にある |
| セキュリティ要件 | 高い(データを外部に出せない) | 緩い |
| タスクの性質 | 情報検索・Q&A | 特定スタイルでの文章生成 |
→ 詳細な比較はRAG vs ファインチューニング徹底比較をご覧ください。
—
RAG導入のご相談
AQUA合同会社のRAG構築サービス
AQUA合同会社は、製造業・金融・医療・法務など幅広い業界でRAG導入実績を持つAI開発企業です。
サービスの特徴
- 業界特化の知見:業界固有の要件を理解した最適な設計
- Azure OpenAI対応:エンタープライズグレードのセキュリティ
- PoC〜本番まで一貫支援:企画・設計・開発・運用をワンストップで
- 精度改善サポート:導入後の継続的なチューニング支援
対応可能な規模
中小企業の部門導入から、大企業の全社展開まで幅広く対応しています。
「自社にRAGは向いているのか?」「どれくらいの効果が見込めるのか?」——まずは無料相談でお気軽にご相談ください。
—
まとめ:RAGは「AI活用の基盤技術」
本記事のポイントをまとめます。
☑️ RAGとは:外部データを検索し、その情報を元にAIが回答を生成する技術
☑️ なぜ必要か:LLMの知識カットオフ、社内情報アクセス不可、ハルシネーションを解決
☑️ 6つのメリット:最新情報対応、ハルシネーション抑制、セキュリティ、コスト効率、透明性、柔軟性
☑️ 費用相場:初期50〜2,000万円、月額5〜200万円(規模により変動)
☑️ 成功の鍵:課題の明確化→データ棚卸し→スモールスタート→効果測定→段階的拡大
☑️ 導入率:2024年12月時点で企業の22.1%が活用中(前年比5倍以上)
RAGは、ChatGPTなどのLLMを「自社専用のAIアシスタント」に進化させる基盤技術です。2025年以降、RAGの導入はさらに加速すると予測されています。
本記事を参考に、ぜひ自社でのRAG導入を検討してみてください。業界別の詳細な活用事例は、上記でご紹介した各専門記事もあわせてご覧ください。