
「社内データをAIに活用したい」——多くの企業が抱えるこの課題を解決する技術が、RAG(Retrieval-Augmented Generation:検索拡張生成)です。ChatGPTに代表される大規模言語モデル(LLM)は驚異的な言語能力を持つ一方で、社内の独自データを知らない、情報が古い、事実と異なる回答を生成するといった根本的な課題を抱えています。RAGは、外部の知識ベースから関連情報を検索し、それを根拠としてAIに回答させることで、これらの課題を一挙に解決します。
RAGの市場規模は急速に拡大しています。MarketsandMarketsの調査によると、RAG市場は2025年の19億ドル(約2,850億円)から2030年には98.6億ドル(約1兆4,790億円)へと成長し、年平均成長率(CAGR)は38.8%に達すると予測されています。日本国内でも、エクサウィザーズの調査によるとRAG導入率は2024年5月時点の4%から同年12月には22.1%へと急増しました。グローバルでは、Databricks「State of Data+AI」レポートが示すとおり、企業の60%以上が既にRAGを導入済みまたは導入を計画しています。
本記事では、RAGの基本概念から最新の技術動向、導入方法までを体系的に解説します。AI(人工知能)の基礎知識がある方を対象としていますが、専門用語はその都度補足するため、初めての方でも理解できる内容です。
この記事でわかること
- RAGの定義と、なぜ今企業に必要とされているのか
- LLM単体の3つの限界とRAGによる解決アプローチ
- 検索・拡張・生成の3ステップで理解するRAGの仕組み
- Naive RAGからAgentic RAGまで——4世代の進化の全体像
- RAG・ファインチューニング・ロングコンテキストの正しい使い分け
- RAGの7つのメリットと5つの限界
RAGとは?——30秒でわかる基本概念
RAGの定義と名前の由来
RAG(Retrieval-Augmented Generation)は、日本語で「検索拡張生成」と訳される技術です。名前のとおり、Retrieval(検索)によってAugmented(拡張)されたGeneration(生成)を実現します。一言で表現すれば、「AIに図書館の司書を付ける技術」です。
RAGの概念は、2020年にMeta AI(旧Facebook AI Research)の研究チームが発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」(Lewis et al., NeurIPS 2020)で初めて提唱されました。この論文は、パラメトリックメモリ(LLMの学習済み知識)とノンパラメトリックメモリ(外部の検索可能な文書データベース)を組み合わせることで、知識集約型タスクの精度を飛躍的に向上させることを実証しました。
従来のLLMは、学習時に取り込んだ情報だけを頼りに回答を生成します。これは、膨大な書籍を暗記した人が記憶だけで質問に答えるようなものです。一方RAGは、質問を受けるたびに関連する資料を検索し、その内容を参照しながら回答を組み立てます。図書館で資料を調べてから回答する司書のように、根拠に基づいた正確な情報を提供できるのです。
RAGとチャットボットの違い
RAGは従来型チャットボットと根本的に異なります。ルールベースのチャットボットはあらかじめ用意されたシナリオに沿って応答するだけで、想定外の質問には対応できません。一方、LLM(大規模言語モデル)ベースのチャットボットは柔軟な応答が可能ですが、学習データに含まれない情報は回答できず、誤った情報を自信満々に語る「ハルシネーション」のリスクがあります。RAGはこの両者の弱点を補い、社内データや最新情報を根拠とした正確かつ柔軟な応答を実現します。
なぜRAGが必要なのか——LLM単体の3つの限界
RAGの価値を正しく理解するには、まずLLM単体で運用した場合にどのような問題が生じるかを知る必要があります。企業がLLMを業務に導入する際に直面する、3つの根本的な限界を解説します。
限界1——ハルシネーション(幻覚)
LLMは、学習データに基づいて統計的に「もっともらしい」テキストを生成する仕組みです。そのため、正確な情報を持たないトピックについても、あたかも事実であるかのような回答を生成することがあります。これがハルシネーション(幻覚)と呼ばれる現象です。
スタンフォード大学HAI(Human-Centered Artificial Intelligence)の研究によると、主要なLLMにおけるハルシネーション発生率は、タスクの種類やモデルによって異なるものの、事実確認が必要な質問では無視できない頻度で発生することが報告されています。法務、医療、金融といった正確性が生命線の業務領域では、この問題は致命的です。RAGは、検索された実際の文書を根拠として回答を生成するため、ハルシネーションを大幅に抑制します。
限界2——知識のカットオフ
LLMの知識には「賞味期限」があります。モデルは特定の時点までのデータで学習されており、それ以降に発生した出来事や更新された情報を知りません。例えば、2024年に学習が完了したモデルに2025年の法改正について質問しても、正確な回答は得られません。
ビジネスの現場では、製品の仕様変更、価格改定、法規制の更新、競合の動向など、常に最新の情報に基づいた意思決定が求められます。RAGは外部データソースをリアルタイムに参照するため、知識のカットオフという制約を完全に克服します。データベースの情報を更新するだけで、AIの回答も自動的に最新化されるのです。
限界3——社内データへのアクセス不可
LLMはインターネット上の公開データで学習されています。つまり、企業の社内マニュアル、議事録、顧客データ、製品仕様書といった非公開の情報は一切含まれていません。LLMの仕組み上、これらの情報に基づく回答を期待することは原理的に不可能です。
RAGは、社内のナレッジベース、ドキュメント管理システム、データベースなどを検索対象として接続することで、この問題を解決します。しかも、社内データをLLMの学習データに含める必要がないため、機密情報が外部に漏洩するリスクを最小限に抑えられます。データは検索時に参照されるだけで、モデル自体には取り込まれないからです。
RAGの仕組み——検索・拡張・生成の3ステップ
RAGのアーキテクチャは、大きく分けて「事前準備(インデックス構築)」と「推論時処理」の2つのフェーズで構成されます。ここでは、それぞれのフェーズを技術的な詳細とともに解説します。
フェーズ1——インデックス構築(データの準備)
RAGを機能させるためには、まず検索対象となるデータを準備する必要があります。このプロセスは以下の4ステップで進行します。
1. ドキュメントの読み込み(Document Loading)
PDF、Word、HTML、データベース、Notion、Confluenceなど、さまざまな形式のドキュメントを読み込みます。企業が保有するナレッジは多様なフォーマットに分散しているため、各形式に対応したローダー(読み込みモジュール)を使用します。
2. チャンキング(Chunking)
読み込んだドキュメントを、意味のある単位に分割します。LLMのコンテキストウィンドウには制限があるため、文書全体をそのまま渡すことはできません。一般的には200〜1,000トークン程度のチャンク(断片)に分割し、前後のチャンクとオーバーラップ(重複部分)を持たせることで、文脈の断絶を防ぎます。チャンキング戦略の良し悪しがRAG全体の精度に直結するため、文書の構造や用途に応じた慎重な設計が求められます。
3. 埋め込み(Embedding)
分割されたチャンクを、埋め込みモデル(Embedding Model)を使って高次元のベクトル(数値の配列)に変換します。例えば、「RAGとは検索拡張生成の技術です」というテキストは、[0.23, -0.51, 0.87, …] のような数百〜数千次元のベクトルに変換されます。意味的に類似したテキストは、ベクトル空間上で近い位置に配置されるため、後の検索フェーズで「意味の近さ」に基づく検索が可能になります。
4. ベクトルデータベースへの格納
生成されたベクトルを、元のテキストやメタデータとともにベクトルデータベース(Vector DB)に格納します。Pinecone、Weaviate、Qdrant、Milvus、ChromaDBなどの専用データベースが、高速な近似最近傍(ANN:Approximate Nearest Neighbor)検索を提供します。
フェーズ2——検索と拡張(Retrieval & Augmentation)
インデックス構築が完了したら、ユーザーからの質問に応答するフェーズに入ります。
1. クエリの埋め込み
ユーザーの質問文を、インデックス構築時と同じ埋め込みモデルでベクトルに変換します。同一のモデルを使用することで、質問とドキュメントが同じベクトル空間上で比較可能になります。
2. 類似検索(Similarity Search)
変換されたクエリベクトルと、データベース内の全ベクトルとの類似度を計算し、最も関連性の高いチャンクをTop-K件(通常3〜10件)取得します。類似度の計算にはコサイン類似度やドット積が使われます。
3. コンテキスト注入(Context Injection)
取得されたチャンクを、ユーザーの質問とともにプロンプトに組み込みます。「以下の情報を参考に、ユーザーの質問に回答してください」という指示とともに、検索結果をLLMに渡します。これが「拡張(Augmentation)」のステップです。
フェーズ3——生成(Generation)
拡張されたプロンプトを受け取ったLLMは、検索された文書の内容を根拠として回答を生成します。このとき、LLMは自身のパラメトリック知識(学習済みの知識)と、プロンプトに含まれるコンテキスト(検索結果)の両方を活用します。プロンプト設計によって、回答には出典情報を含めるよう指示することも可能で、ユーザーは回答の根拠を確認できるようになります。
具体例で理解するRAGの動作
ここでは、社内FAQ検索のシナリオで具体的な動作を見てみましょう。
社員が「リモートワーク時の交通費精算はどうすればいいですか?」と質問したとします。RAGシステムは次のように動作します。まず、この質問文をベクトルに変換し、社内規程データベースに対して類似検索を実行します。「在宅勤務規程」「交通費精算ガイドライン」「経費申請マニュアル」といった関連ドキュメントのチャンクが検索結果として返されます。次に、これらのチャンクをコンテキストとしてLLMに渡し、回答を生成させます。結果として、「在宅勤務規程第5条に基づき、リモートワーク日の交通費は実費精算となります。申請は経費精算システムから…」のように、具体的な社内規程を引用した正確な回答が得られます。
RAGの4世代——NaiveからAgentic RAGまで
RAGの技術は2020年の提唱以来、急速な進化を遂げています。Gao et al. (2024)のサーベイ論文「Retrieval-Augmented Generation for Large Language Models: A Survey」をはじめとする研究に基づき、RAGの進化を4つの世代に整理します。
第1世代——Naive RAG(2020年〜)
Lewis et al.の原論文に端を発する最初期のRAGアーキテクチャです。「検索(Retrieve)→ 読み込み(Read)→ 生成(Generate)」という単純な直線的パイプラインで構成されます。ユーザーの質問をそのままベクトル検索に渡し、取得されたチャンクをプロンプトに追加してLLMに生成させるという、最もシンプルな実装です。
Naive RAGは導入の容易さが最大の利点ですが、いくつかの明確な弱点があります。検索クエリの最適化が行われないため検索精度が低い、無関係なチャンクがノイズとして混入する、チャンク間の冗長性を排除できないといった問題が顕在化します。とはいえ、概念実証(PoC)や小規模な用途では今なお有効なアプローチです。
第2世代——Advanced RAG(2023年〜)
Naive RAGの課題を克服するため、検索の前後に最適化プロセスを追加したのがAdvanced RAGです。主な改善点は3つあります。
Pre-retrieval(検索前)最適化:ユーザーの質問をそのまま検索に使うのではなく、クエリの書き換え(Query Rewriting)、拡張(Query Expansion)、分解(Query Decomposition)を行います。曖昧な質問を検索に適した形に変換することで、検索精度が大幅に向上します。
検索手法の高度化:ベクトル検索(セマンティック検索)に加えて、BM25などのキーワードベース検索を組み合わせたハイブリッド検索を採用します。それぞれの検索手法の強みを活かし、弱みを補完し合うことで、検索の再現率と精度の両方を改善します。
Post-retrieval(検索後)最適化:検索結果に対してリランキング(Re-ranking)を実施し、質問との関連性が高い順に並び替えます。さらに、冗長なチャンクの除去や、コンテキスト圧縮によってLLMに渡す情報の質を高めます。
第3世代——Modular RAG(2024年〜)
Modular RAGは、RAGパイプラインの各構成要素をモジュール化し、用途に応じて柔軟に組み替えられるアーキテクチャです。検索モジュール、生成モジュール、ルーティングモジュールなどが独立したコンポーネントとして設計され、レゴブロックのように組み合わせを変更できます。
例えば、質問の種類に応じて異なる検索戦略に自動ルーティングしたり、複数のインデックス(社内文書、FAQ、製品カタログなど)を動的に切り替えたりすることが可能です。この柔軟性により、単一のRAGシステムが多様なユースケースに対応できるようになりました。
第4世代——Agentic RAG(2025年〜)
最新のトレンドであるAgentic RAGは、AIエージェントの自律的な判断能力をRAGに統合したアーキテクチャです。従来のRAGが「1回の検索→1回の生成」という固定的なフローであったのに対し、Agentic RAGはエージェントが検索の必要性を自ら判断し、複数回の検索を反復的に実行し、検索結果の品質を自己評価して必要に応じて再検索を行います。
MicrosoftのGraphRAGに代表されるように、知識グラフとの統合によるエンティティ間の関係性を活用した推論や、複数のエージェントが協調して複雑な質問に段階的に回答するマルチエージェント型RAGも登場しています。Agentic RAGは、単純な質問応答を超えて、複雑な調査・分析タスクにAIを活用する道を開いています。
| 特性 | Naive RAG(第1世代) | Advanced RAG(第2世代) | Modular RAG(第3世代) | Agentic RAG(第4世代) |
|---|---|---|---|---|
| 登場時期 | 2020年 | 2023年 | 2024年 | 2025年 |
| パイプライン構造 | 直線的・固定 | 前後処理追加 | モジュール交換可能 | 自律的・動的 |
| 検索手法 | 単一ベクトル検索 | ハイブリッド検索 | 動的ルーティング | マルチソース反復検索 |
| クエリ最適化 | なし | 書き換え・拡張 | 分岐・フィルタリング | エージェント判断 |
| 検索後処理 | なし | リランキング・圧縮 | モジュール選択 | 自己評価・再検索 |
| 導入難易度 | 低 | 中 | 中〜高 | 高 |
| 適用シーン | PoC・小規模FAQ | 本番運用全般 | マルチドメイン | 複雑な調査・分析 |
RAG vs ファインチューニング vs ロングコンテキスト
LLMに外部知識を活用させる手法はRAGだけではありません。ファインチューニング(Fine-Tuning)とロングコンテキストウィンドウの活用という2つの代替アプローチが存在します。それぞれの特性を理解し、適切に使い分けることが、AIシステムの設計において極めて重要です。
ファインチューニングとの違い
ファインチューニングは、既存のLLMに対して特定のドメインのデータを追加学習させる手法です。モデルのパラメータ自体を更新するため、学習後はプロンプトに情報を注入しなくても、そのドメインに関する知識を「内在化」した状態で回答できるようになります。
しかし、ファインチューニングにはいくつかの重大な課題があります。まず、高品質な学習データの準備に膨大なコストと時間がかかります。次に、情報が更新されるたびに再学習が必要であり、リアルタイムな情報反映は困難です。さらに、ファインチューニングはモデルの「振る舞い」(応答スタイルや専門用語の使い方)を調整するのに適しているものの、大量の事実情報を正確に記憶させるのには向いていません。ファインチューニング後もハルシネーションは発生し得るため、事実の正確性が求められる用途では単体での使用は推奨されません。
一方、RAGとファインチューニングは排他的な関係ではなく、組み合わせることでさらに高い精度を達成できます。ファインチューニングで応答品質を底上げし、RAGで最新の事実情報を注入するというハイブリッドアプローチは、多くの先進的な企業で採用されています。
ロングコンテキストウィンドウとの違い
近年、LLMのコンテキストウィンドウが劇的に拡大しています。Google DeepMindが開発したGemini 1.5 Proは100万トークン(約75万語)のコンテキストを処理でき、AnthropicのClaude 3.5は20万トークンに対応しています。「大量のドキュメントをそのままコンテキストに入れれば、RAGは不要ではないか」という疑問は自然なものです。
しかし、ロングコンテキストアプローチには明確な制約があります。第一に、コンテキストが長くなるほどAPIコスト(トークン課金)が増大し、運用コストが急激に膨らみます。第二に、LLMは長いコンテキストの中間部分にある情報を見落とす傾向があること(「Lost in the Middle」問題)が研究で示されています。第三に、処理時間(レイテンシ)が大幅に増加します。
したがって、ロングコンテキストは少数の大きなドキュメントを深く分析するタスク(長文の契約書レビュー、論文の要約など)に適しており、数千〜数万件のドキュメントから適切な情報を見つけ出す検索タスクにはRAGが圧倒的に有利です。
3手法の使い分け判断基準
最適な手法は、データの性質、更新頻度、求められる精度、コスト制約によって異なります。頻繁に更新される事実情報を扱う場合はRAG、モデルの応答品質を根本的に改善したい場合はファインチューニング、少数のドキュメントに対する深い分析が必要な場合はロングコンテキストが適しています。実際の本番環境では、これらを組み合わせるケースが最も多く見られます。詳しい比較と選定ガイドは、RAGとファインチューニングの徹底比較で解説しています。
| 比較項目 | RAG | ファインチューニング | ロングコンテキスト |
|---|---|---|---|
| 知識の更新 | データベース更新で即座に反映 | 再学習が必要(数時間〜数日) | 入力ドキュメントの差し替えで対応 |
| コスト | ベクトルDB+API費用(低〜中) | GPU計算コスト(高) | トークン課金(使用量に比例) |
| データ量の上限 | 数百万件以上でもスケール可能 | 学習データ量に依存(上限あり) | コンテキスト長に制約(最大100万トークン) |
| ハルシネーション抑制 | 高い(出典ベースで回答) | 限定的(依然として発生) | 中程度(Lost in the Middle問題) |
| レイテンシ | 検索時間の追加(数百ms) | 追加レイテンシなし | コンテキスト長に比例して増加 |
| 最適な用途 | 社内FAQ、ナレッジ検索、最新情報活用 | 応答スタイルの調整、専門領域の口調 | 長文分析、契約書レビュー、論文要約 |
| 導入難易度 | 中(ベクトルDB構築が必要) | 高(MLエンジニアリングが必要) | 低(APIに渡すだけ) |
RAGのメリットと限界
ここまでRAGの仕組みと進化を見てきました。RAGの導入を検討するにあたり、そのメリットと限界を正確に把握することが不可欠です。
RAGの7つのメリット
1. 最新情報への即座対応
RAGはデータベースの更新によって即座に最新情報を反映できます。LLMの再学習を待つ必要がなく、データソースを更新するだけでAIの回答が最新化されます。製品情報の変更、法改正、社内規程の更新など、リアルタイム性が求められるビジネス環境において決定的な利点です。
2. ハルシネーションの大幅抑制
RAGは検索された実際のドキュメントを根拠として回答を生成するため、LLM単体と比較してハルシネーションの発生率を大幅に低減します。特に、「根拠が見つからない場合は回答しない」というガードレールを設定することで、誤情報の提供リスクをさらに抑えることが可能です。
3. セキュリティとプライバシーの確保
社内データをLLMの学習データに含める必要がないため、機密情報の漏洩リスクが低く抑えられます。データは検索時にのみ参照され、外部のモデルプロバイダーにデータを渡す範囲を制御できます。アクセス制御やデータの暗号化と組み合わせることで、厳格なセキュリティ要件にも対応可能です。
4. コスト効率の高さ
ファインチューニングと比較して、RAGの導入・運用コストは大幅に低く抑えられます。高価なGPUリソースを用いた再学習が不要であり、ベクトルデータベースの運用コストも比較的低廉です。また、検索で絞り込んだ関連情報のみをLLMに渡すため、ロングコンテキストアプローチよりもトークン使用量を最適化できます。
5. 透明性と説明責任(出典明示)
RAGは回答の根拠となったドキュメントを明示できるため、「なぜその回答に至ったのか」をユーザーが検証できます。この透明性は、AIの信頼性を担保する上で極めて重要であり、規制産業(金融、医療、法務)でのAI活用において特に求められる特性です。
6. 柔軟なカスタマイズ
検索対象のデータソースを変更するだけで、RAGシステムの知識領域を柔軟にカスタマイズできます。部署ごとに異なるナレッジベースを接続したり、ユーザーの権限に応じて参照可能なデータを制限したりと、きめ細かな制御が可能です。
7. スケーラビリティ
ベクトルデータベースは数百万件以上のドキュメントにスケールでき、データ量の増加に対して検索速度を大きく犠牲にすることなく対応できます。新しいドキュメントの追加もインデックスへの差分反映で完了するため、運用の手間が最小限に抑えられます。
RAGの5つの限界
1. 検索品質への依存
RAGの回答品質は、検索フェーズの精度に直結します。「Garbage In, Garbage Out」の原則どおり、関連性の低いドキュメントが検索されれば、LLMの回答品質も低下します。検索モジュールの設計とチューニングがRAG全体の成否を分けるため、単にツールを導入するだけでは十分な効果は得られません。
2. チャンキング戦略の難しさ
ドキュメントを適切なサイズと粒度で分割するチャンキングは、RAGにおける最大の技術的課題の一つです。チャンクが小さすぎると文脈が失われ、大きすぎると無関係な情報がノイズとして混入します。最適なチャンキング戦略はドキュメントの種類や質問の傾向によって異なり、試行錯誤が必要です。
3. レイテンシの増加
RAGは検索フェーズが追加されるため、LLM単体での回答と比較してレスポンスタイムが長くなります。ベクトル検索自体は数十ミリ秒で完了しますが、リランキングやコンテキスト圧縮などの後処理を含めると、数百ミリ秒から数秒の遅延が生じる場合があります。リアルタイム性が厳しく求められるユースケースでは、キャッシュ戦略やインフラの最適化が必要です。
4. 構造化データの扱いにくさ
RAGはテキストベースの非構造化データ(文書、FAQ、マニュアルなど)に最適化されています。売上データ、在庫情報、KPIダッシュボードのような構造化データを扱うには、Text-to-SQLやデータ分析エージェントとの組み合わせが必要となり、アーキテクチャが複雑化します。
5. マルチモーダル対応の未成熟
現在のRAGは主にテキストデータを対象としています。図表、画像、動画、音声といったマルチモーダルなコンテンツを含むドキュメントに対しては、それぞれのモダリティに対応した埋め込みモデルやインデックス戦略が必要ですが、この分野はまだ発展途上にあります。マルチモーダルRAGの研究は急速に進展しているものの、本番環境で安定稼働させるにはまだ技術的なハードルが残されています。
| メリット | 限界 |
|---|---|
| 最新情報への即座対応——データベース更新のみ | 検索品質への依存——検索精度がボトルネック |
| ハルシネーション大幅抑制——出典ベースの回答 | チャンキング戦略の難しさ——最適な分割は試行錯誤 |
| セキュリティ確保——データは検索時のみ参照 | レイテンシの増加——検索処理分の遅延 |
| コスト効率——再学習不要で低コスト運用 | 構造化データの扱いにくさ——別途アプローチ必要 |
| 透明性——回答根拠を明示可能 | マルチモーダル対応の未成熟——テキスト中心 |
| 柔軟なカスタマイズ——データソース切替で対応 | |
| スケーラビリティ——数百万件以上に対応 |
RAGの主要技術スタック——ベクトルDB・埋め込みモデル
RAGシステムを本番環境で構築するには、複数の技術コンポーネントを適切に組み合わせる必要があります。ここでは、RAGを支える5つの技術レイヤーと、各レイヤーの主要プロダクトを体系的に解説します。
5つの技術レイヤー
RAGの技術スタックは、以下の5層で構成されます。各レイヤーが連携し、エンドツーエンドのパイプラインを形成します。
Layer 1:データソース——PDF、データベース、Web、API、CSV、Notionなど、企業が保有するあらゆる非構造化・半構造化データが入力となります。データの多様性に対応するコネクタの充実度が、システムの汎用性を左右します。
Layer 2:チャンキングと前処理——取り込んだデータをテキスト分割(チャンキング)し、メタデータの抽出やクリーニングを行います。チャンクサイズの設定は検索精度に直結するため、LlamaIndexの検証では512トークン前後が多くのユースケースで最適とされています。
Layer 3:埋め込みモデル(Embedding Models)——テキストを高次元のベクトル(数値の配列)に変換するモデルです。OpenAIのtext-embedding-3-large、GoogleのGemini Embedding、Cohereのembed-v3、Voyage AIなどが主要な選択肢です。日本語の場合、多言語対応モデルの選定が特に重要になります。
Layer 4:ベクトルデータベース——生成されたベクトルを格納し、類似度検索を高速に実行するための専用データベースです。次項で6製品を詳しく比較します。
Layer 5:LLMオーケストレーション——各レイヤーを統合し、検索からプロンプト構築、LLM呼び出し、回答生成までの一連のパイプラインを管理するフレームワークです。
主要ベクトルデータベース6製品比較
ベクトルデータベースはRAGの心臓部です。DB-Enginesのランキングでも専用ベクトルDBの注目度は急上昇しており、2024年から2025年にかけて市場は急速に成熟しています。以下に代表的な6製品を比較します。
| 製品名 | 種別 | 主要特徴 | 対応言語 | 価格モデル | 適した用途 |
|---|---|---|---|---|---|
| Qdrant | OSS | Rust製の高速処理・フィルタリング | Python, JS, Go, Rust | 無料(OSS)/ クラウド従量課金 | 高性能が求められる本番環境 |
| Pinecone | マネージド | フルマネージド・サーバーレス | Python, JS, Java, Go | フリーミアム / 従量課金 | 迅速な立ち上げ・運用負荷軽減 |
| Weaviate | OSS | マルチモーダル対応・GraphQL API | Python, JS, Go, Java | 無料(OSS)/ クラウド従量課金 | 画像・テキスト混在のマルチモーダル検索 |
| pgvector | OSS(拡張) | PostgreSQL拡張・既存DB統合 | SQL + 各種ORM | 無料(PostgreSQL拡張) | 既にPostgreSQLを利用中の環境 |
| Chroma | OSS | 軽量・開発者フレンドリー | Python, JS | 無料(OSS) | PoC・プロトタイピング |
| Milvus | OSS | 大規模分散処理・10億ベクトル対応 | Python, Java, Go, JS | 無料(OSS)/ Zillizクラウド | 数億件以上の大規模検索 |
オーケストレーションフレームワーク
RAGパイプライン構築のLayer 5を担うのが、オーケストレーションフレームワークです。主要な2つのフレームワークを紹介します。
LangChainは、RAGパイプラインの構築において最も広く採用されているフレームワークです。豊富なインテグレーション(LLMプロバイダー、ベクトルDB、データローダーなど)を備え、プロンプトテンプレート、チェーン、エージェントといった抽象化レイヤーにより、複雑なRAGパイプラインを宣言的に構築できます。LangSmithによるモニタリングやLangGraphによるステートフルなエージェント構築もエコシステムに含まれます。
LlamaIndexは、データインデックスの構築と検索に特化したフレームワークです。多様なデータソースへのコネクタ(LlamaHub)、柔軟なインデックス構造(ベクトル、キーワード、ナレッジグラフなど)、高度な検索戦略(ハイブリッド検索、再ランキング)を提供します。特にドキュメント検索を主軸としたRAGシステムでは、LlamaIndexの方がシンプルに構築できるケースが多く見られます。
両者は競合というよりも補完関係にあり、LlamaIndexでインデックスを構築し、LangChainでパイプライン全体を管理するという組み合わせも一般的です。
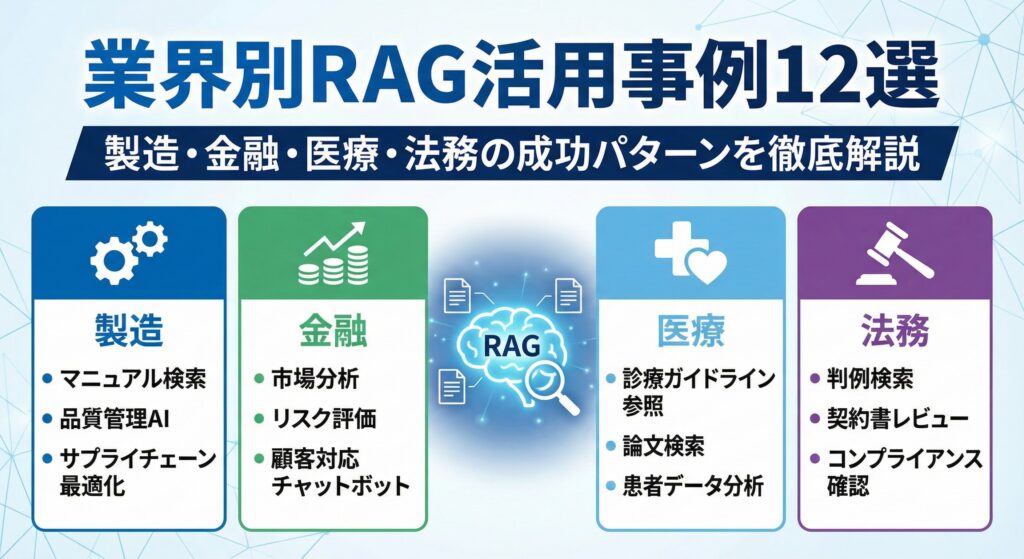
業界別活用事例——法律・医療・金融・製造
RAGは業界を問わず、「膨大な専門知識を正確に検索・活用する」という共通課題に対する解決策として急速に導入が進んでいます。ここでは、4つの主要業界における具体的な活用事例と成果を紹介します。
法律業界——判例検索と契約レビューの革新
法律業界は、RAGの恩恵を最も直接的に受ける分野の一つです。弁護士の業務時間のうち、判例や法令の検索に費やされる割合は非常に大きく、RAGによる自動化のインパクトは計り知れません。
LegalOn Cloudは、AIによる契約書レビューサービスとしてRAGを活用し、数万件の契約テンプレートや判例データベースから関連する条文やリスク条項を瞬時に検索・提示します。契約レビューにかかる時間を最大90%削減した事例が報告されています。
弁護士ドットコムも、法律相談AIにRAGを組み込み、過去の相談事例や法令データベースから最適な回答を生成する仕組みを構築しています。従来のキーワード検索では見つけにくかった類似判例を、意味ベースの検索で高精度に取得できる点が大きな強みです。法律業界向けRAG導入ガイドでは、さらに詳しい事例と導入ステップを解説しています。
医療業界——臨床判断支援と最新論文アクセス
医療分野では、日々更新される膨大な医学論文や臨床ガイドラインへのアクセスが、適切な診断・治療の鍵を握ります。NYU Langone Healthは、RAGを活用した臨床判断支援システムを導入し、医師が患者の症状を入力すると、PubMedや院内の電子カルテデータから関連する論文・症例を即座に検索して提示する仕組みを実現しました。
特に希少疾患の診断では、個々の医師の経験だけでは対応が難しいケースでも、世界中の症例報告をRAGが横断検索することで、診断候補の提示精度が大幅に向上しています。また、薬剤の相互作用チェックにおいても、最新の添付文書情報と患者の服薬履歴を突き合わせるRAGシステムが、安全性の向上に貢献しています。
金融業界——コンプライアンスとリスク管理
金融業界では、規制文書の膨大さと改正頻度の高さがRAG導入の大きな動機となっています。JPMorgan ChaseのCOiN(Contract Intelligence)プラットフォームは、RAGの先駆的事例として知られています。同社の報告によると、法務部門において年間36万時間の手作業を削減し、商業融資契約の解析を数秒で完了できるようになりました。
国内でも、メガバンク各社がコンプライアンスチェックにRAGを導入し始めています。金融庁のガイドラインや業界自主規制ルールの改正内容を即座にナレッジベースに反映し、行員からの問い合わせに対して最新の規制解釈を提示する仕組みが整備されつつあります。
製造業——技術継承とナレッジマネジメント
製造業が直面する「2025年問題」——熟練技術者の大量退職による技術・ノウハウの喪失——は、RAGが解決すべき最も切実な課題の一つです。
AGCは、数十年にわたる製造プロセスの技術文書や品質管理レポートをRAGシステムに統合し、若手技術者がベテランの暗黙知にアクセスできる環境を構築しました。設備トラブル発生時に、過去の類似事例と対処法を即座に検索できるため、ダウンタイムの短縮にも直結しています。
中外製薬では、研究開発部門における論文・特許検索にRAGを活用し、新薬の候補化合物に関連する先行研究を効率的に特定する仕組みを構築しています。人材業界においてもRAGの横展開が進んでおり、人材業界のRAG活用ガイドで詳しく解説しています。
日本企業のRAG導入動向
日本国内のRAG導入は急速に加速しています。エクサウィザーズの調査によると、国内企業のRAG導入率は2024年5月時点のわずか4%から、同年12月には22.1%へと急増しました。わずか7ヶ月で5倍以上の伸びを記録しています。
日本経済新聞の報道でも、大手企業を中心にRAG導入が加速していることが頻繁に取り上げられており、2025年は「RAG導入元年」とも呼ばれています。業種別では、金融・製造・法律の3業界が先行しており、今後はサービス業や小売業への拡大が見込まれます。
RAGの評価方法——RAGASフレームワーク
RAGシステムを構築したら、次に問われるのは「そのRAGは本当に高品質な回答を返しているのか?」という評価の問題です。RAGの評価は従来のNLP評価とは異なるアプローチが必要であり、ここでは業界標準となりつつあるRAGASフレームワークを解説します。
なぜRAGの評価が難しいのか
RAGシステムの評価が通常のAIシステムより複雑な理由は、評価すべきポイントが複数あることにあります。検索コンポーネントが適切な文書を取得できているか(検索の質)と、LLMがその文書をもとに正確な回答を生成できているか(生成の質)の両方を別々に、かつ統合的に評価する必要があるのです。検索が完璧でも生成で情報を歪めれば意味がなく、逆に生成能力が高くても検索が不適切な文書を返せば正確な回答は期待できません。
RAGASの4つの評価指標
RAGAS(Retrieval Augmented Generation Assessment)は、RAGシステムの品質を定量的に評価するためのオープンソースフレームワークです。以下の4つの指標でRAGの品質を多角的に測定します。
1. Context Precision(検索精度)——検索結果の上位に、質問に関連する文書がどれだけ正確に配置されているかを測定します。スコアが高いほど、ノイズの少ない高精度な検索結果が得られていることを意味します。検索結果の順位(ランキング)も評価対象に含まれます。
2. Context Recall(検索網羅性)——正解回答を生成するために必要な情報が、検索結果にどれだけ網羅的に含まれているかを測定します。スコアが高いほど、必要な情報の取りこぼしが少ないことを示します。
3. Answer Faithfulness(回答忠実度)——生成された回答が、検索で取得した文書の内容に忠実であるかを測定します。LLMがハルシネーション(根拠のない情報の捏造)を起こしていないかを検出する重要な指標です。スコアが高いほど、回答が検索結果に基づいた信頼性の高いものであることを意味します。
4. Answer Relevancy(回答関連性)——生成された回答が、ユーザーの元の質問に対して的確に答えているかを測定します。検索結果に忠実であっても、質問の意図からずれた回答は低スコアとなります。
評価の実践ポイント
RAGASを活用した評価を成功させるための実践的なポイントは3つあります。第一に、評価データセットの構築です。実際のユーザー質問と期待回答のペアを最低50件以上用意し、業務領域の多様な質問パターンを網羅します。第二に、継続的モニタリングです。本番環境のRAGパイプラインにRAGASを組み込み、各指標のスコアを定期的に計測・可視化します。第三に、指標ごとの改善アクションです。Context Precisionが低ければチャンキング戦略を見直し、Answer Faithfulnessが低ければプロンプトテンプレートを改善するなど、指標に基づいた具体的な改善サイクルを回します。
RAG導入の進め方——3フェーズロードマップ
RAG導入を成功させるには、段階的なアプローチが不可欠です。いきなり全社展開を目指すのではなく、小さく始めて確実に成果を積み上げるロードマップを以下に示します。
Phase 1——PoC(概念実証):1~2ヶ月
最初のフェーズでは、RAGの技術的な実現可能性と効果を検証します。対象とするユースケースを1つに絞り、限定的なデータセット(数百~数千件)を用いてプロトタイプを構築します。この段階では、Chroma + LangChainのような軽量な構成で十分です。
具体的には、社内FAQの自動回答や、特定部門のマニュアル検索など、成果が測定しやすく、データの準備が比較的容易なユースケースを選定します。PoCの成否判断基準は事前に明確化しておくことが重要で、「既存のキーワード検索と比較して回答精度が20%以上向上する」といった定量的な指標を設定します。費用目安は100万~300万円(クラウドインフラ+開発工数)です。
Phase 2——パイロット運用:2~3ヶ月
PoCで有効性が確認できたら、限定的な実ユーザー(1部署、20~50名程度)に展開するパイロット運用に移行します。この段階で、本番環境に近いインフラ構成(Qdrant/PineconeなどのベクトルDB、RAGASによる評価パイプライン)を整備し、実際の業務フローにRAGを組み込みます。
パイロット期間中は、ユーザーフィードバックの収集体制を構築し、回答精度の継続的モニタリング、チャンキング戦略の最適化、プロンプトテンプレートの改善を繰り返します。セキュリティレビューやアクセス制御の設計もこの段階で完了させます。費用目安は300万~800万円です。
Phase 3——本番展開:3~6ヶ月
パイロットの成果をもとに全社展開へと進みます。データソースの拡充、ユーザー数のスケーリング、SLAの策定、運用ドキュメントの整備を行います。高可用性構成(冗長化、オートスケーリング)への移行や、既存システムとのAPI連携も本フェーズで完了させます。
全社展開後も改善は止まりません。ユーザーの利用パターンを分析し、新しいユースケースの発掘、対象データの拡張、モデルのアップグレードなどを継続的に実施します。費用目安は500万~2,000万円(年間運用コスト含む)です。中小企業向けRAG導入ガイドではより少ない予算での導入方法を、AIビジネスツール一覧では活用できる既存サービスを、AI導入コスト完全ガイドではコスト試算の詳細を解説しています。
| フェーズ | 期間 | 目標 | 主要タスク | 成果物 | 費用目安 |
|---|---|---|---|---|---|
| Phase 1:PoC | 1~2ヶ月 | 技術的実現可能性の検証 | ユースケース選定、データ準備、プロトタイプ構築 | PoCレポート、精度評価結果 | 100万~300万円 |
| Phase 2:パイロット | 2~3ヶ月 | 実業務での有効性実証 | 本番構成整備、フィードバック収集、精度改善 | パイロット報告書、運用手順書 | 300万~800万円 |
| Phase 3:本番展開 | 3~6ヶ月 | 全社スケーリングと運用安定化 | インフラ拡張、API連携、SLA策定、運用体制構築 | 本番システム、SLA文書、運用マニュアル | 500万~2,000万円 |
「RAG is dead?」論争——最新動向と未来
2024年以降、AI業界では「RAGは不要になるのではないか」という議論が活発化しています。その背景にある技術トレンドと、RAGの将来展望を分析します。
ロングコンテキストウィンドウの台頭
「RAG is dead」論の最大の根拠は、LLMのコンテキストウィンドウの劇的な拡大です。Google Gemini 1.5 Proは100万トークン(書籍約8冊分)、Anthropic Claudeは20万トークンのコンテキストウィンドウを実現しました。これだけの情報を一度にLLMに投入できるならば、わざわざ検索する必要はないのではないか——これが「RAG不要論」の核心です。
実際に、少量のドキュメント(数十ページ程度)を対象とする質問応答であれば、全文をコンテキストに投入するロングコンテキストアプローチがRAGと同等以上の精度を出すケースもあります。しかし、企業の現実的なユースケースを考えると、この議論には大きな落とし穴があります。
RAGが「死なない」5つの理由
1. コスト効率——100万トークンのコンテキストに全文を投入するコストは、1回のAPI呼び出しで数ドルに達します。1日に数千件のクエリを処理する企業システムでは、月間コストが数百万円に膨れ上がります。RAGであれば、関連する数チャンク(数千トークン)のみを投入するため、コストは数十分の1に抑えられます。
2. リアルタイム更新——LLMのコンテキストに投入するデータは、毎回最新の状態を用意する必要があります。一方RAGは、ベクトルDBのインデックスを更新するだけで常に最新情報にアクセスできます。日々更新される社内ドキュメントや顧客データを扱う場合、RAGのアーキテクチャは圧倒的に有利です。
3. スケーラビリティ——企業が保有するドキュメント総量は、数百万ページに及ぶことも珍しくありません。100万トークンのコンテキストウィンドウでも、全社のナレッジベースを一度に投入することは物理的に不可能です。RAGは、数億件のドキュメントからミリ秒単位で関連情報を検索できるスケーラビリティを持ちます。
4. アクセス制御——企業環境では、ユーザーの権限に応じて参照可能な情報を制限する必要があります。RAGは検索段階でアクセス制御を適用できるため、機密情報の不正な露出を防止できます。全文コンテキスト投入ではこの制御が困難です。
5. 監査可能性——RAGは「どの文書のどの部分を根拠として回答を生成したか」を明示的に追跡できます。金融や医療など規制産業では、この監査可能性(トレーサビリティ)が法的要件として求められるケースが増えています。
RAGの未来——エージェンティック化と市場成長
「RAG is dead」どころか、RAGの市場は今後10年で爆発的に成長すると予測されています。Cognitive Market Researchの調査によると、RAGの市場規模は2035年までに404.7億ドル(約6兆円)に達すると予測されています。
技術面では、RAGの「エージェンティック化」が最大のトレンドです。Microsoft GraphRAGはナレッジグラフとRAGを融合し、文書間の関係性を構造的に捉えた高度な検索を実現しています。また、Anthropic MCP(Model Context Protocol)は、LLMが外部ツールやデータソースに標準化されたプロトコルでアクセスする仕組みを提供し、RAGパイプラインの構築をさらに容易にしています。
RAGは「死ぬ」のではなく、「進化する」のです。単純な検索+生成から、AIエージェントが自律的に最適な検索戦略を選択・実行するAgentic RAGへと発展し、企業のAI基盤としてより不可欠な存在になっていくでしょう。生成AIのビジネス活用完全ガイドでは、RAGを含む生成AI技術の包括的な活用戦略を解説しています。
導入時の注意点とベストプラクティス
RAGの技術的な可能性を理解した上で、実際の導入を成功に導くための注意点とベストプラクティスを整理します。多くの企業がPoCで失敗する原因は、技術そのものではなく、導入プロセスの設計にあります。
データ品質が成否を分ける
RAGの回答品質は、入力データの品質に直接比例します。「Garbage in, garbage out(ゴミを入れればゴミが出る)」の原則は、RAGにおいて特に顕著に当てはまります。フォーマットが統一されていないドキュメント、古い情報が混在するナレッジベース、重複コンテンツが放置されたデータソースからは、どれほど高度なRAGパイプラインを構築しても高品質な回答は得られません。
Gartnerは、2025年末までに生成AIプロジェクトの30%がPoC(概念実証)の段階で放棄されると予測しています。その主要因の一つがデータ品質の問題であり、技術検証の前にデータの棚卸しと整理を徹底することが、プロジェクト成功の第一歩です。
7つのベストプラクティス
1. 明確なユースケース定義——「AIを導入したい」という曖昧な目標ではなく、「カスタマーサポートの初回回答率を現在の40%から70%に引き上げる」といった具体的なKPIを設定します。ユースケースが明確であれば、必要なデータソース、評価基準、成功条件がおのずと定まります。
2. データクレンジングの徹底——RAG導入前に、対象ドキュメントの棚卸し、重複排除、古い情報の更新・削除、フォーマットの統一を実施します。この工程を省略すると、後工程でのチューニングコストが指数関数的に増大します。
3. チャンキング戦略の最適化——文書の性質に応じた最適なチャンクサイズとオーバーラップ設定を検証します。法律文書は段落単位、FAQ文書はQ&Aペア単位、技術マニュアルはセクション単位など、ドキュメントタイプごとに最適解は異なります。
4. 評価パイプラインの構築——RAGASなどの評価フレームワークを導入初期から組み込み、検索精度・回答品質を定量的にモニタリングする体制を整えます。定量評価なくして改善サイクルは回りません。
5. ユーザーフィードバックループ——回答に対する「役に立った/役に立たなかった」のフィードバックボタンや、正解回答の報告機能を実装し、実際のユーザー評価を継続的に収集します。このデータが評価データセットの拡充と品質改善の原動力となります。
6. セキュリティ設計——ベクトルDBへのアクセス制御、プロンプトインジェクション対策、個人情報のマスキング処理を設計段階から組み込みます。特に、RAGが社内の機密情報にアクセスする構成では、権限管理の設計が極めて重要です。
7. 段階的スケーリング——前述の3フェーズロードマップに沿って、PoC→パイロット→本番展開と段階的に拡大します。一気に全社展開を目指す「ビッグバン方式」は失敗リスクが高く、小さな成功を積み重ねるアプローチが推奨されます。プロンプトエンジニアリング完全ガイドでは、RAGのプロンプト設計に関するベストプラクティスを詳しく解説しています。
まとめ——RAGはAI活用の「必修科目」
この記事の要点
- RAGの技術スタックは、データソース・チャンキング・埋め込みモデル・ベクトルDB・オーケストレーションの5層で構成される
- ベクトルDBはQdrant、Pinecone、Weaviate、pgvector、Chroma、Milvusの6製品が主要選択肢であり、用途に応じた選定が重要
- 法律・医療・金融・製造の各業界でRAGの実践的な導入が進み、具体的な成果が報告されている
- RAGASフレームワークの4指標(検索精度・検索網羅性・回答忠実度・回答関連性)で品質を定量評価できる
- 導入はPoC(1~2ヶ月)、パイロット(2~3ヶ月)、本番展開(3~6ヶ月)の3フェーズで段階的に進める
- ロングコンテキストの台頭にも関わらず、コスト効率・リアルタイム更新・スケーラビリティ・アクセス制御・監査可能性の5つの理由でRAGは「死なない」
- データ品質の確保と7つのベストプラクティスの実践が、導入成功の鍵を握る
- RAGの市場規模は2035年までに404.7億ドル(約6兆円)に成長し、エージェンティック化が進む
RAGは、単なる技術トレンドではなく、企業がAIを実務に活用するための基盤技術です。LLMの限界を補い、自社データの価値を最大化し、根拠に基づいた信頼性の高いAI回答を実現する——その能力は、業界を問わず、あらゆる企業にとって不可欠なものになりつつあります。
重要なのは、完璧なシステムを一度に構築しようとするのではなく、小さく始めて、評価と改善を繰り返しながら段階的に拡張していくことです。本記事で解説した技術スタック、評価フレームワーク、3フェーズロードマップを参考に、まずは自社のユースケースに最適なPoCから着手してみてください。
RAG導入の次のステップとして、中小企業向けRAG導入完全ガイドでは、より具体的な導入手順と予算に応じた構成パターンを解説しています。